









字节突发大模型,为何上来就打价格战?
前言:
中国大型语言模型算法的开发已迈入成熟阶段,初期工作已圆满完成,已从单纯的研发阶段顺利过渡至广泛普及阶段。
这一显著的进展意味着,业内参与者需进一步加快步伐,在竞争中抢占先机,以便使更多开发者乃至广大公众能够便捷地调用大型模型,并将其广泛应用于各类开发实践之中。
作者 | 方文三
图片来源 | 网 络

大模型落地与成本之间的博弈
当前,行业内普遍关注的一个核心议题是,大型模型如何有效融入并推动各行各业的创新发展。
在AI大模型时代,底层技术尚处于快速迭代和动态发展的阶段。
这要求企业在运用大模型技术时,不仅要考虑推理过程中产生的技术成本,还需寻找产品与市场需求的最佳契合点。
要实现大模型技术对世界的深刻变革,关键在于确保该技术具有足够低的访问成本;
从而吸引足够多的用户加入到其技术生态中,为繁荣的生态发展奠定坚实基础。
值得注意的是,大模型价格的降低背后,算力成本的下降趋势也是行业发展的重要驱动力。
与GPT-4 Turbo相比,GPT-4o在速度上实现了两倍的提升,速率限制高出五倍,且价格减半。
此外,OpenAI还取消了使用ChatGPT的注册限制,使得更多用户能够便捷地体验到其服务。
OpenAI的这一系列举措,无疑给国内的大模型技术企业带来了深刻的启示和挑战。
它们不仅需要思考如何进一步提升技术水平,还需在价格上做出更有竞争力的调整,以应对激烈的市场竞争。
先To C再To B的字节大模型
豆包,原名云雀大模型,于去年8月正式推出,成为国内首批成功通过算法备案的大模型之一。
与此同时,字节近期积极推出多款AI产品,其中包括具备AI生图功能的[星绘]、支持AI角色互动的[话炉]以及对标小红书的[可颂]等。
从云雀大模型的研发,到豆包大模型服务平台的上线,再到一系列产品应用的落地,字节在AIGC领域的布局展现出全方位覆盖的战略态势。
值得注意的是,字节在打造大模型的同时,也致力于开发爆款应用。
此次,字节推出的[系统型超级应用]主要面向C端市场,以满足广大用户的需求。
目前,国内众多大模型厂商主要基于基础模型自研通用大模型。
以百度文心一言为例,该模型需要经过大量学习训练后方能实际应用,主要面向B端企业用户。
然而,豆包大模型的概念更为广泛,它更接近于AGI,即更全面的人工智能系统。
基于豆包大模型,字节不仅推出了AI对话助手[豆包],还构建了AI应用开发平台[扣子]、互动娱乐应用[猫箱]以及AI创作工具如[星绘]、[即梦]等。
此外,豆包大模型已接入抖音、番茄小说、飞书、巨量引擎等50余个业务场景。
通过超低价及嵌入应用等策略,字节明确表示其大模型面向C端市场。
未来,字节或将借助庞大的用户基础进一步推动大模型的发展,并逐步拓展B端客户。
一旦这个以大模型驱动的AI应用体系成熟,字节将有望打造一个强大的系统型超级应用。
从单点突破向全面拓展,字节的大模型生态正在逐渐丰富。值得强调的是,此次豆包大模型首次对外提供服务,展示了其在多个领域的广泛应用能力。
其类型包括通用模型Pro/lite、角色扮演模型、语音识别模型、语音合成模型、声音复刻模型、文生图模型、Function call模型、向量化模型等。
然而,尽管大模型应用前景广阔,但与移动互联网数亿级用户量相比,其发展仍处于早期阶段。
未来一年,大模型有望在更多企业场景中实现从概念验证到实际生产系统的跨越。

价格战让AI技术竞赛进入新阶段
在中国互联网大厂中,字节跳动率先在大模型市场发起了价格战,展现出独特的竞争策略。
与其他公司不同,字节跳动并未在大模型发布时过多关注各种测评和榜单,而是选择了更为务实的路线,注重实际应用效果。
随着腾讯、字节跳动等互联网巨头相继完成大模型在公司内部的试水阶段,并将产品推向市场,积极探索商业化路径,这场AI技术竞赛正步入新的发展阶段。
观察发现,包括腾讯、京东、阿里巴巴和百度等在内的科技巨头,在过去的一年多时间里,都将大模型竞争的核心聚焦于提升模型训练效率以及降低大模型推理成本上。
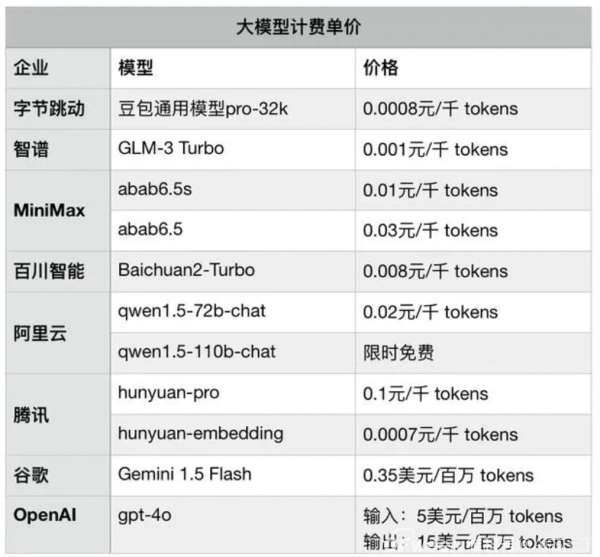
近日,幻方量化旗下的DeepSeek推出了第二代MoE模型DeepSeek-V2,该模型API定价为每百万Tokens输入1元、输出2元(32K上下文),价格仅为GPT-4 Turbo的近百分之一,展现出显著的成本优势。
此外,智谱AI大模型开放平台也推出了全新的价格体系,新注册用户可获得的tokens额度从500万提升至2500万,同时个人版GLM-3Turbo模型产品的价格也从5元/百万tokens降低至1元/百万tokens,进一步降低了用户的使用成本。
值得一提的是,字节跳动近期首次亮相的豆包大模型,其定价策略也引发了广泛关注。
豆包主力模型Pro-32k版本模型推理输入价格仅为0.0008元/千Tokens,这意味着用户仅需支付0.8厘即可处理超过1500个汉字,相比行业同等模型便宜了99.3%。
而128k型号的定价也仅为0.005元/千Tokens,比行业价格低了95.8%。
与百度、阿里巴巴等同规格32k模型0.12元/千tokens的定价相比,字节跳动的豆包大模型在价格上具备显著优势。
这种激进的价格策略似乎表明,大模型厂商正在通过降低价格来拓展市场份额,尽管这可能会对他们的利润空间造成一定压力。
在今日头条和抖音的崛起过程中,字节跳动成功捕获了用户规模的红利。
如今,该公司意图将这一成功策略应用于AI大模型领域,将价格战作为撬动用户数量的新支点,并期望借此契机推动火山引擎云服务实现增长。
通过实施模型结构的优化、分布式推理以及混合调度等一系列举措,字节跳动显著降低了大模型的推理成本。
随着模型调用量的不断增加,成本优化的空间也进一步得到拓展。

AI大模型竞速已经进入应用层
自今年起,随着大模型能力的显著增强,其应用环节已显露出至关重要的作用。
在当前市场中,众多企业均对大模型抱有浓厚的兴趣,并期望尝试运用。然而,由于潜在的不确定性风险,这些企业在推进相关项目时表现得相对谨慎。
目前看来,基于大型模型的能力特性,数字化水平较高、数据基础扎实、知识体系复杂的行业和场景往往成为大模型技术率先落地的领域,并充分发挥出其应用价值。
通过实际应用为突破口,大模型在降低成本、提高效率、推动业务创新和增强用户体验等多个维度展现出巨大的价值,为业界和大众带来更为具体和直观的落地实现方式。
类似的大模型在实际应用中发挥关键作用的案例屡见不鲜。
沿着探索的方向可以发现,应用实践是大模型技术不断磨砺和完善的重要途径。
大模型所赋能的高质量应用,具备高度的专业化、低成本和高可靠性,能够有效解决行业痛点问题。
从文本生成到图像生成,再到视频生成,大模型通过海量应用不断解锁新的能力,充分展现出其广阔的发展前景。
从更长远的视角来看,大模型在应用层面的加速落地将促进新质生产力的形成,进一步推动数字经济的提质升级。

结尾:
大模型的价格战在字节亲自参与后,已逐渐推向高潮。
这场关于大模型的产业竞争,已从去年的[百模大战]逐步演进,如今正聚焦于场景落地与应用竞速赛。
部分资料参考:全天候科技:《字节挑起了一场战争》,字母榜:《降价是字节AI的出路吗?》,雷锋网:《闷声狂奔一年,字节大模型的进阶之路》,伯虎财经:《To C大模型,将是字节跳动新[王牌]?》,硅星GenAI:《字节内部AI[赛马]结束,大模型全跟豆包姓》,科技说说:《字节跳动发布豆包,AI大模型进入应用[深水区]?》
原文标题 : AI芯天下丨分析丨字节突发大模型,为何上来就打价格战?

 分享
分享








最新活动更多
-
3月27日立即报名>> 【工程师系列】汽车电子技术在线大会
-
4月30日立即下载>> 【村田汽车】汽车E/E架构革新中,新智能座舱挑战的解决方案
-
5月15-17日立即预约>> 【线下巡回】2025年STM32峰会
-
即日-5.15立即报名>>> 【在线会议】安森美Hyperlux™ ID系列引领iToF技术革新
-
5月15日立即下载>> 【白皮书】精确和高效地表征3000V/20A功率器件应用指南
-
5月16日立即参评 >> 【评选启动】维科杯·OFweek 2025(第十届)人工智能行业年度评选







发表评论
请输入评论内容...
请输入评论/评论长度6~500个字
暂无评论
暂无评论