БОЮФжиЕувЊНВЕФетЦЊТлЮФЪЧЃК ·Unifying Language Learning Paradigm...
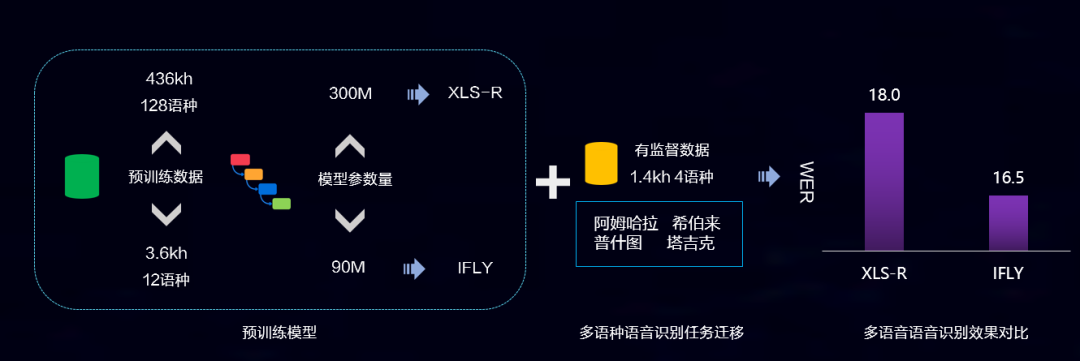 НќФъРДЃЌвдГЌДѓЙцФЃФЃаЭЁЂКЃСПбЕСЗЪ§ОнЁЂздМрЖНбЇЯАзМдђЮЊЬиЕуЕФЮоМрЖНдЄбЕСЗФЃаЭБИЪмЙизЂЁЃОпгаИпЭЈгУадЕФЮоМрЖНдЄбЕСЗДѓФЃаЭЃЌНсКЯжЊЪЖКЭКЃСПЪ§ОнНјааШкКЯбЇЯАЃЌЭЈЙ§ЬсШЁдЪМЪ§ОнЕФ...
НќФъРДЃЌвдГЌДѓЙцФЃФЃаЭЁЂКЃСПбЕСЗЪ§ОнЁЂздМрЖНбЇЯАзМдђЮЊЬиЕуЕФЮоМрЖНдЄбЕСЗФЃаЭБИЪмЙизЂЁЃОпгаИпЭЈгУадЕФЮоМрЖНдЄбЕСЗДѓФЃаЭЃЌНсКЯжЊЪЖКЭКЃСПЪ§ОнНјааШкКЯбЇЯАЃЌЭЈЙ§ЬсШЁдЪМЪ§ОнЕФ...
зюНќКЭЭЌЪТСФЬьЃЌСФЕНвЛДЮУцЪдЪБЃЌЭЌЪТзїЮЊУцЪдЙйЃЌЬсЮЪСЫвЛИіаЁЮЪЬтЃКЁИШчЙћФугЕгаЕФдЄбЕСЗЕФгяСЯКЭЯТгЮШЮЮёЕФгяСЯЗжВМВювьКмДѓЃЌФуЛсдѕУДзіЁЙЁИФЧЫћД№ЩЯРДСЫТ№ЁЙЮвЮЪЕНЁИУЛгаЁЙЫћЫЕ...
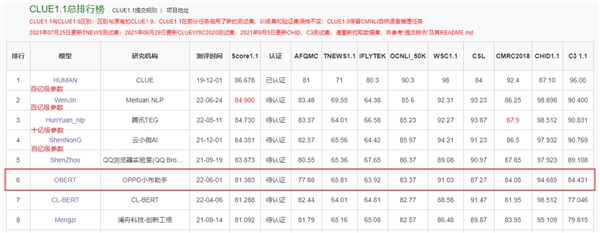 НќШеЃЌOPPOаЁВМжњЪжЭХЖгКЭЛњЦїбЇЯАВПСЊКЯЭъГЩСЫЪЎвкВЮЪ§ФЃаЭЁАOBERTЁБЕФдЄбЕСЗЃЌвЕЮёЩЯШЁЕУСЫ4ЃЅвдЩЯЕФЬсЩ§ЃЛдкаавЕЖдБШЦРВтжаЃЌOBERTдООгжаЮФгябдРэНтВтЦРЛљзМCLU...
НќШеЃЌOPPOаЁВМжњЪжЭХЖгКЭЛњЦїбЇЯАВПСЊКЯЭъГЩСЫЪЎвкВЮЪ§ФЃаЭЁАOBERTЁБЕФдЄбЕСЗЃЌвЕЮёЩЯШЁЕУСЫ4ЃЅвдЩЯЕФЬсЩ§ЃЛдкаавЕЖдБШЦРВтжаЃЌOBERTдООгжаЮФгябдРэНтВтЦРЛљзМCLU...
 НёШеЃЌББОЉЕчзгЙЄГЬзмЬхбаОПЫљЗЂВМЁАащФтТЯЩњЃдЊгюжцаЭЌНЈФЃЗТецЗНЗЈбаОПЁБЕФОќЙЄашЧѓЙЋИцЃЌВЩЙКНзЖЮЮЊдЄбаЁЃИљОнЙЋИцЃЌЩЯЪіЯюФПЕФбаОПФПБъЮЊЃКеыЖддЊгюжцЁЂащФтТЯЩњЕШаТаЭащФтЛЗОГ...
НёШеЃЌББОЉЕчзгЙЄГЬзмЬхбаОПЫљЗЂВМЁАащФтТЯЩњЃдЊгюжцаЭЌНЈФЃЗТецЗНЗЈбаОПЁБЕФОќЙЄашЧѓЙЋИцЃЌВЩЙКНзЖЮЮЊдЄбаЁЃИљОнЙЋИцЃЌЩЯЪіЯюФПЕФбаОПФПБъЮЊЃКеыЖддЊгюжцЁЂащФтТЯЩњЕШаТаЭащФтЛЗОГ...
ФПТМвЛЁЂЮЊЪВУДвЊmaskЖўЁЂетаЉФъpaperжаГіЯжЙ§ЕФmaskЗНЪН2ЃЎ1 padding PaddingЃmask2ЃЎ2 sequence maskЃКtransforme...
НќШе,АЂРяАЭАЭДяФІдКЙЋВМЖрФЃЬЌДѓФЃаЭ M6 зюаТНјеЙ,ЦфВЮЪ§вбДгЭђвкдОЧЈжС 10 Эђвк,ГЩЮЊШЋЧђзюДѓЕФ AI дЄбЕСЗФЃаЭЁЃОнЙЋПЊзЪСЯЯдЪО,M6 ЪЧДяФІдКбаЗЂЕФЭЈгУадШЫЙЄжЧ...
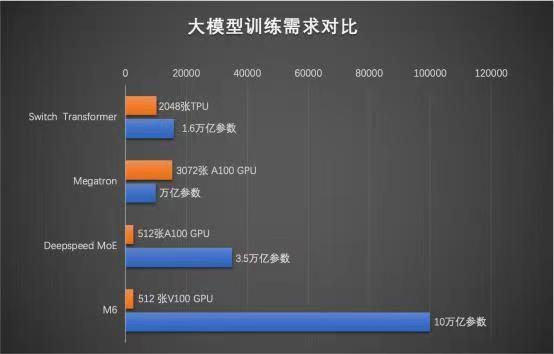 11дТ8ШеЯћЯЂЃЌАЂРяАЭАЭДяФІдКЙЋВМЖрФЃЬЌДѓФЃаЭM6зюаТНјеЙЃЌЦфВЮЪ§вбДгЭђвкдОЧЈжС10ЭђвкЃЌЙцФЃдЖГЌЙШИшЁЂЮЂШэДЫЧАЗЂВМЕФЭђвкМЖФЃаЭЃЌГЩЮЊШЋЧђзюДѓЕФAIдЄбЕСЗФЃаЭЁЃЭЌЪБЃЌM6...
11дТ8ШеЯћЯЂЃЌАЂРяАЭАЭДяФІдКЙЋВМЖрФЃЬЌДѓФЃаЭM6зюаТНјеЙЃЌЦфВЮЪ§вбДгЭђвкдОЧЈжС10ЭђвкЃЌЙцФЃдЖГЌЙШИшЁЂЮЂШэДЫЧАЗЂВМЕФЭђвкМЖФЃаЭЃЌГЩЮЊШЋЧђзюДѓЕФAIдЄбЕСЗФЃаЭЁЃЭЌЪБЃЌM6...
зд2018ФъЙШИшЗЂВМBERTвдРД,дЄбЕСЗДѓФЃаЭОЙ§Ш§ФъЕФЗЂеЙ,вдЧПДѓЕФЫуЗЈаЇЙћ,ЯЏОэСЫNLPЮЊДњБэЕФИїДѓAIАёЕЅгыВтЪдЪ§ОнМЏЁЃ2020ФъOpenAIЗЂВМЕФNLPДѓФЃаЭGP...
ИХвЊЗжЯэЮвЕФжЊЪЖЃЌЪЙгУДјгаЪОР§ДњТыЦЌЖЮЕФЧЈвЦбЇЯАж№ВНдкGoogle colabжаЕФздЖЈвхЪ§ОнМЏЩЯбЕСЗStyleGANШчКЮЪЙгУдЄбЕСЗЕФШЈжиДгздЖЈвхЪ§ОнМЏжаЩњГЩЭМЯёЪЙгУВЛЭЌЕФ...
ТлЮФБъЬт:AMBERT: A Pre-trained Language Model with Multi-Grained Tokenization(ЖрСЃЖШЗжДЪЕФдЄбЕСЗгябд...
ЮЊСЫГфЗжбаОПДѓЙцФЃдЄбЕСЗКЭЧЈвЦбЇЯАЕФФкдкЛњРэКЭЙцТЩЃЌРДздЙШИшЕФбаОПШЫдБЗЂБэСЫвЛЦЊУћЮЊBigTransferЕФТлЮФЃЌЬНЫїСЫШчКЮгааЇРћгУГЌГЃЙцЕФЭМЯёЪ§ОнЙцФЃРДЖдФЃаЭНјаадЄбЕСЗ...
ОЭдкЙШИшЁЂШ§аЧКЭЮЂШэМЬајдкИіШЫЕчФдКЭвЦЖЏЩшБИЩЯДѓСІЭЦЙуШЫЙЄжЧФмЩњГЩММЪѕЕФЭЌЪБЃЌЦЛЙћвВМгШыСЫетвЛааСаЃЌЭЦГіСЫOpenELMЁЃ етЪЧвЛИіШЋаТЕФПЊдДДѓаЭгябдФЃаЭЃЈLLMЃЉЯЕСа...
Naveen RaoвбОдкНЈСЂШЫЙЄжЧФмММЪѕКЭЙЋЫОЗНУцгаЪЎЖрФъЕФОбщЁЃЫћДДСЂСЫ Nervana SystemsЃЈБЛгЂЬиЖћЪеЙКЃЉКЭ MosaicMLЃЈБЛDatabricksЪе...
зїепЃКаЁбв БрМЃКВЪдЦ 4дТ19ШеЃЌFacebookФИЙЋЫОMetaжиАѕЭЦГіСЫLlama3ЁЃ МДБуДѓМвЯждкЖдгкДѓГЇКЭОоЭЗЦЕЗБЕќДњAIФЃаЭЕФааЮЊвбОМћЙжВЛЙжЃЌMetaЕФ...
зїеп|ебОѕ AIаТаЧOpenAIзюНќгаЕуЭЗЬлЃЌВЛНіЙЋЫОКЭCEOБЛТэЫЙПЫЦ№ЫпЃЌЦфШЭЗВњЦЗGPT-4дкадФмКЭМлИёЩЯОљУцСйОКељЖдЪжЕФГхЛїЁЃ НќЦкЃЌГЩСЂВЛЕНвЛФъЕФЗЈЙњШЫЙЄжЧФм...
зїеп |КСФЉжЧааЪ§ОнжЧФмПЦбЇМв КиЯшБрМ |ЯщЭўзюНќЃЌЬиЫЙРFSD V12ЕФЗЂВМв§ЗЂСЫвЕНчЖдЖЫЕНЖЫздЖЏМнЪЛЕФШШвщЃЌвЕНчЗзЗзВТВтFSD V12ЕФЧПДѓФмСІЪЧШчКЮбЕСЗГіРДЕФЁЃДг...
“дЊгюжцЕФПЊЭиеп”ЪЧЮвУЧеыЖддЊгюжцЕФЗЂеЙЖјЩшСЂЕФзЈРИЃЌжївЊУцЯђФЧаЉЩюЭкдЊгюжцВњвЕЛђепдкдЊгюжцНјаа“ЬдН№”ЕФДгвЕепЃЌЗжЯэетаЉ...
зїеп |еХЯщЭў БрМ |ЕТаТ 2023ФъЃЌдкБШбЧЕЯФЧДЮЙЋВМжЧМнЪ§ОнЙцФЃКѓЃЌжЧФмЛЏЯТАыГЁЕФеНЖЗОЭе§ЪНДђЯьСЫЁЃ ШчНёЃЌздЖЏМнЪЛе§дкбизХЬиЫЙРЬсГіЕФЁИBEV+Tran...
12дТЙШИшЕФДѓгябдФЃаЭGeminiвЛОЗЂВМОЭв§ЗЂаавЕШШвщЁЃдкЖрИіДѓФЃаЭЦРВтАёЕЅжаЃЌЙШИшGemini UltraАцБОГЌЙ§СЫGPT-4ЃЌвбгаГЩЮЊДѓФЃаЭ“аТЭѕ&rd...
ЮЊЛ§МЋЯьгІЙЄаХВПЕШЪЎЦпВПУХСЊКЯгЁЗЂЕФЁЖЁАЛњЦїШЫ+ЁБгІгУааЖЏЪЕЪЉЗНАИЁЗЃЌЭЦЖЏЁАЛњЦїШЫ+ ...
ЮФЕЕРДдДЃКРћдЊКр
