









一文详解Flink知识体系
本文目录:
一、Flink简介
二、Flink 部署及启动
三、Flink 运行架构
四、Flink 算子大全
五、流处理中的 Time 与 Window
六、Flink 状态管理
七、Flink 容错
八、Flink SQL
九、Flink CEP
十、Flink CDC
十一、基于 Flink 构建全场景实时数仓
十二、Flink 大厂面试题
Flink 涉及的知识点如下图所示,本文将逐一讲解:
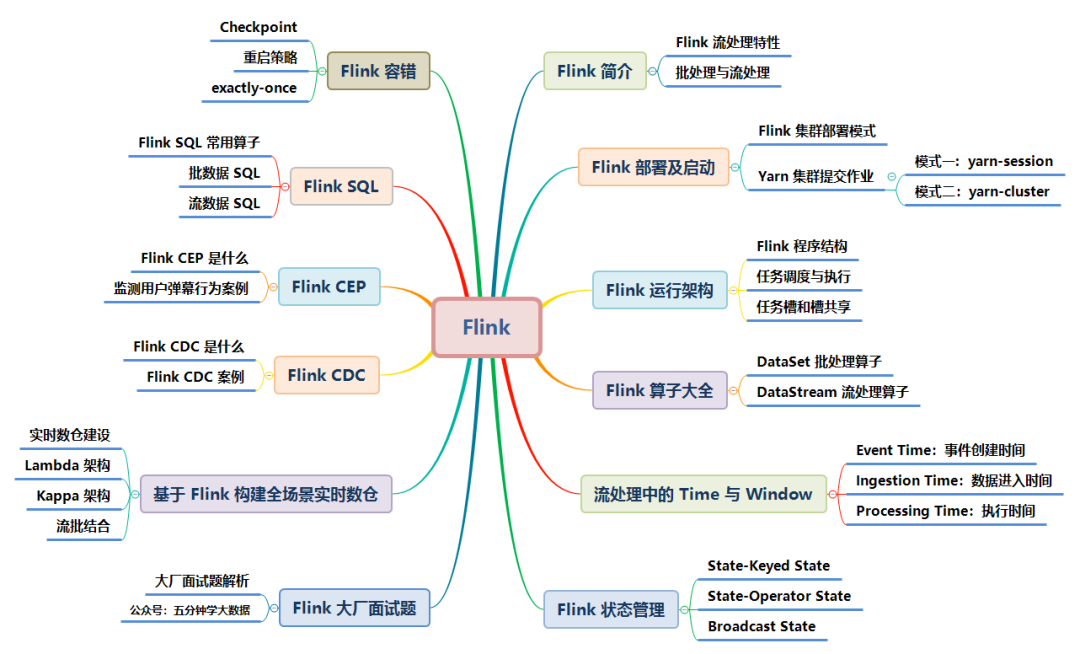
本文档参考了 Flink 的官网及其他众多资料整理而成,为了整洁的排版及舒适的阅读,对于模糊不清晰的图片及黑白图片进行重新绘制成了高清彩图。
一、Flink 简介1. Flink 发展
这几年大数据的飞速发展,出现了很多热门的开源社区,其中著名的有 Hadoop、Storm,以及后来的 Spark,他们都有着各自专注的应用场景。Spark 掀开了内存计算的先河,也以内存为赌注,赢得了内存计算的飞速发展。Spark 的火热或多或少的掩盖了其他分布式计算的系统身影。就像 Flink,也就在这个时候默默的发展着。
在国外一些社区,有很多人将大数据的计算引擎分成了 4 代,当然,也有很多人不会认同。我们先姑且这么认为和讨论。
首先第一代的计算引擎,无疑就是 Hadoop 承载的 MapReduce。这里大家应该都不会对 MapReduce 陌生,它将计算分为两个阶段,分别为 Map 和 Reduce。对于上层应用来说,就不得不想方设法去拆分算法,甚至于不得不在上层应用实现多个 Job 的串联,以完成一个完整的算法,例如迭代计算。
由于这样的弊端,催生了支持 DAG 框架的产生。因此,支持 DAG 的框架被划分为第二代计算引擎。如 Tez 以及更上层的 Oozie。这里我们不去细究各种 DAG 实现之间的区别,不过对于当时的 Tez 和 Oozie 来说,大多还是批处理的任务。
接下来就是以 Spark 为代表的第三代的计算引擎。第三代计算引擎的特点主要是 Job 内部的 DAG 支持(不跨越 Job),以及强调的实时计算。在这里,很多人也会认为第三代计算引擎也能够很好的运行批处理的 Job。
随着第三代计算引擎的出现,促进了上层应用快速发展,例如各种迭代计算的性能以及对流计算和 SQL 等的支持。Flink 的诞生就被归在了第四代。这应该主要表现在 Flink 对流计算的支持,以及更一步的实时性上面。当然 Flink 也可以支持 Batch 的任务,以及 DAG 的运算。
总结:
第 1 代:Hadoop MapReduc 批处理 Mapper、Reducer 2;
第 2 代:DAG 框架(Oozie 、Tez),Tez + MapReduce 批处理 1 个 Tez = MR(1) + MR(2) + ... + MR(n) 相比 MR 效率有所提升;
第 3 代:Spark 批处理、流处理、SQL 高层 API 支持 自带 DAG 内存迭代计算、性能较之前大幅提;
第 4 代:Flink 批处理、流处理、SQL 高层 API 支持 自带 DAG 流式计算性能更高、可靠性更高。
2. 什么是 Flink
Flink 起源于 Stratosphere 项目,Stratosphere 是在 2010~2014 年由 3 所地处柏林的大学和欧洲的一些其他的大学共同进行的研究项目,2014 年 4 月 Stratosphere 的代码被复制并捐赠给了 Apache 软件基金会,参加这个孵化项目的初始成员是 Stratosphere 系统的核心开发人员,2014 年 12 月,Flink 一跃成为 Apache 软件基金会的顶级项目。
在德语中,Flink 一词表示快速和灵巧,项目采用一只松鼠的彩色图案作为 logo,这不仅是因为松鼠具有快速和灵巧的特点,还因为柏林的松鼠有一种迷人的红棕色,而 Flink 的松鼠 logo 拥有可爱的尾巴,尾巴的颜色与 Apache 软件基金会的 logo 颜色相呼应,也就是说,这是一只 Apache 风格的松鼠。

Flink 主页在其顶部展示了该项目的理念:“Apache Flink 是为分布式、高性能、随时可用以及准确的流处理应用程序打造的开源流处理框架”。
Apache Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。Flink 被设计在所有常见的集群环境中运行,以内存执行速度和任意规模来执行计算。
3. Flink 流处理特性
支持高吞吐、低延迟、高性能的流处理
支持带有事件时间的窗口(Window)操作
支持有状态计算的 Exactly-once 语义
支持高度灵活的窗口(Window)操作,支持基于 time、count、session,以及 data-driven 的窗口操作
支持具有 Backpressure 功能的持续流模型
支持基于轻量级分布式快照(Snapshot)实现的容错
一个运行时同时支持 Batch on Streaming 处理和 Streaming 处理
Flink 在 JVM 内部实现了自己的内存管理
支持迭代计算
支持程序自动优化:避免特定情况下 Shuffle、排序等昂贵操作,中间结果有必要进行缓存
4. Flink 基石
Flink 之所以能这么流行,离不开它最重要的四个基石:Checkpoint、State、Time、Window。
首先是 Checkpoint 机制,这是 Flink 最重要的一个特性。Flink 基于Chandy-Lamport算法实现了一个分布式的一致性的快照,从而提供了一致性的语义。Chandy-Lamport 算法实际上在 1985 年的时候已经被提出来,但并没有被很广泛的应用,而 Flink 则把这个算法发扬光大了。
Spark 最近在实现 Continue streaming,Continue streaming 的目的是为了降低它处理的延时,其也需要提供这种一致性的语义,最终采用 Chandy-Lamport 这个算法,说明 Chandy-Lamport 算法在业界得到了一定的肯定。
提供了一致性的语义之后,Flink 为了让用户在编程时能够更轻松、更容易地去管理状态,还提供了一套非常简单明了的 State API,包括里面的有 ValueState、ListState、MapState,近期添加了 BroadcastState,使用 State API 能够自动享受到这种一致性的语义。
除此之外,Flink 还实现了 Watermark 的机制,能够支持基于事件的时间的处理,或者说基于系统时间的处理,能够容忍数据的延时、容忍数据的迟到、容忍乱序的数据。
另外流计算中一般在对流数据进行操作之前都会先进行开窗,即基于一个什么样的窗口上做这个计算。Flink 提供了开箱即用的各种窗口,比如滑动窗口、滚动窗口、会话窗口以及非常灵活的自定义的窗口。
5. 批处理与流处理
批处理的特点是有界、持久、大量,批处理非常适合需要访问全套记录才能完成的计算工作,一般用于离线统计。流处理的特点是无界、实时,流处理方式无需针对整个数据集执行操作,而是对通过系统传输的每个数据项执行操作,一般用于实时统计。
在 Spark 生态体系中,对于批处理和流处理采用了不同的技术框架,批处理由 SparkSQL 实现,流处理由 Spark Streaming 实现,这也是大部分框架采用的策略,使用独立的处理器实现批处理和流处理,而 Flink 可以同时实现批处理和流处理。
Flink 是如何同时实现批处理与流处理的呢?答案是,Flink 将批处理(即处理有限的静态数据)视作一种特殊的流处理。
Flink 的核心计算架构是下图中的 Flink Runtime 执行引擎,它是一个分布式系统,能够接受数据流程序并在一台或多台机器上以容错方式执行。
Flink Runtime 执行引擎可以作为 YARN(Yet Another Resource Negotiator)的应用程序在集群上运行,也可以在 Mesos 集群上运行,还可以在单机上运行(这对于调试 Flink 应用程序来说非常有用)。

上图为 Flink 技术栈的核心组成部分,值得一提的是,Flink 分别提供了面向流式处理的接口(DataStream API)和面向批处理的接口(DataSet API)。因此,Flink 既可以完成流处理,也可以完成批处理。Flink 支持的拓展库涉及机器学习(FlinkML)、复杂事件处理(CEP)、以及图计算(Gelly),还有分别针对流处理和批处理的 Table API。
能被 Flink Runtime 执行引擎接受的程序很强大,但是这样的程序有着冗长的代码,编写起来也很费力,基于这个原因,Flink 提供了封装在 Runtime 执行引擎之上的 API,以帮助用户方便地生成流式计算程序。Flink 提供了用于流处理的 DataStream API 和用于批处理的 DataSet API。值得注意的是,尽管 Flink Runtime 执行引擎是基于流处理的,但是 DataSet API 先于 DataStream API 被开发出来,这是因为工业界对无限流处理的需求在 Flink 诞生之初并不大。
DataStream API 可以流畅地分析无限数据流,并且可以用 Java 或者 Scala 等来实现。开发人员需要基于一个叫 DataStream 的数据结构来开发,这个数据结构用于表示永不停止的分布式数据流。
Flink 的分布式特点体现在它能够在成百上千台机器上运行,它将大型的计算任务分成许多小的部分,每个机器执行一部分。Flink 能够自动地确保发生机器故障或者其他错误时计算能够持续进行,或者在修复 bug 或进行版本升级后有计划地再执行一次。这种能力使得开发人员不需要担心运行失败。Flink 本质上使用容错性数据流,这使得开发人员可以分析持续生成且永远不结束的数据(即流处理)。
二、Flink 部署及启动
Flink 支持多种安装模式:
local(本地)——单机模式,一般不使用;
standalone——独立模式,Flink 自带集群,开发测试环境使用;
yarn——计算资源统一由 Hadoop YARN 管理,生产环境使用。
Flink 集群的安装不属于本文档的范畴,如安装 Flink,可自行搜索资料进行安装。
本节重点在 Flink 的 Yarn 部署模式。
在一个企业中,为了最大化的利用集群资源,一般都会在一个集群中同时运行多种类型的 Workload,可以使用 YARN 来管理所有计算资源。
1. Flink 在 Yarn 上的部署架构

从图中可以看出,Yarn 的客户端需要获取 hadoop 的配置信息,连接 Yarn 的 ResourceManager。所以要设置 YARN_CONF_DIR 或者 HADOOP_CONF_DIR 或者 HADOOP_CONF_PATH,只要设置了其中一个环境变量,就会被读取。如果读取上述的变量失败了,那么将会选择 hadoop_home 的环境变量,会尝试加载$HADOOP_HOME/etc/hadoop 的配置文件。
当启动一个 Flink Yarn 会话时,客户端首先会检查本次请求的资源(存储、计算)是否足够。资源足够将会上传包含 HDFS 及 Flink 的配置信息和 Flink 的 jar 包到 HDFS;
客户端向 RM 发起请求;
RM 向 NM 发请求指令,创建 container,并从 HDFS 中下载 jar 以及配置文件;
启动 ApplicationMaster 和 jobmanager,将 jobmanager 的地址信息写到配置文件中,再发到 hdfs 上;
同时,AM 向 RM 发送心跳注册自己,申请资源(cpu、内存);
创建 TaskManager 容器,从 HDFS 中下载 jar 包及配置文件并启动;
各 task 任务通过 jobmanager 汇报自己的状态和进度,AM 和 jobmanager 在一个容器上,AM 就能掌握各任务的运行状态,从而可以在任务失败时,重新启动任务;
任务完成后,AM 向 RM 注销并关闭自己;
2. 启动集群修改 hadoop 的配置参数:vim etc/hadoop/yarn-site.xml
添加:
修改 Hadoop 的 yarn-site.xml,添加该配置表示内存超过分配值,是否将任务杀掉。
默认为 true。运行 Flink 程序,很容易内存超标,这个时候 yarn 会自动杀掉 job。
修改全局变量 /etc/profile:
添加:export HADOOP_CONF_DIR=/export/servers/hadoop/etc/Hadoop
YARN_CONF_DIR 或者 HADOOP_CONF_DIR 必须将环境变量设置为读取 YARN 和 HDFS 配置
启动 HDFS、zookeeper(如果是外置 zookeeper)、YARN 集群;
使用 yarn-session 的模式提交作业。
Yarn Session 模式提交作业有两种方式:yarn-session 和 yarn-cluster
3. 模式一: yarn-session
特点:
使用 Flink 中的 yarn-session(yarn 客户端),会启动两个必要服务 JobManager 和 TaskManagers;
客户端通过 yarn-session 提交作业;
yarn-session 会一直启动,不停地接收客户端提交的任务;
如果拥有有大量的小作业,适合使用这种方式。

在 flink 目录启动 yarn-session:
bin/yarn-session.sh -n 2 -tm 800 -jm 800 -s 1 -d
-n 表示申请 2 个容器
-s 表示每个容器启动多少个 slot 离模式,表示以后台程
-tm 表示每个 TaskManager 申请 800M 内存
-d 分序方式运行
使用 flink 提交任务:
bin/flink run examples/batch/WordCount.jar
如果程序运行完了,可以使用 yarn application -kill application_id 杀掉任务:
yarn application -kill application_1554377097889_0002
bin/yarn-session.sh -n 2 -tm 800 -s 1 -d 意思是:
同时向 Yarn 申请 3 个 container(即便只申请了两个,因为 ApplicationMaster 和 Job Manager 有一个额外的容器。一旦将 Flink 部署到 YARN 群集中,它就会显示 Job Manager 的连接详细信息),其中 2 个 Container 启动 TaskManager(-n 2),每个 TaskManager 拥有两个 Task Slot(-s 1),并且向每个 TaskManager 的 Container 申请 800M 的内存,以及一个 ApplicationMaster(Job Manager)。
4. 模式二: yarn-cluster
特点:
直接提交任务给 YARN;
大作业,适合使用这种方式;
会自动关闭 session。
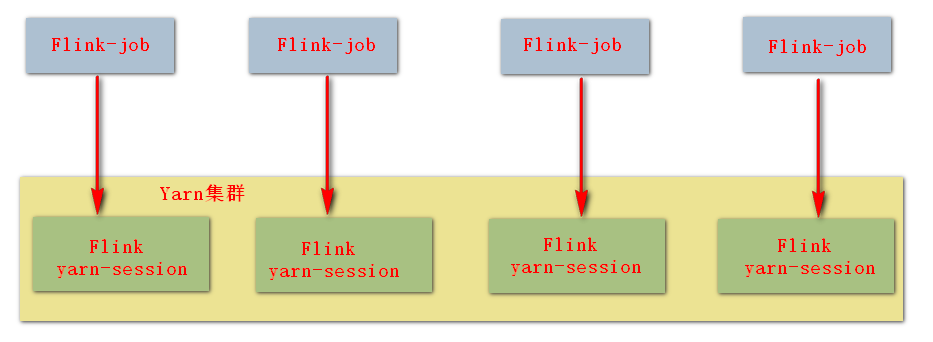
使用 flink 直接提交任务:
bin/flink run -m yarn-cluster -yn 2 -yjm 800 -ytm 800 /export/servers/flink-1.6.0/examples/batch/WordCount.jar
-yn 表示 TaskManager 的个数
注意:
在创建集群的时候,集群的配置参数就写好了,但是往往因为业务需要,要更改一些配置参数,这个时候可以不必因为一个实例的提交而修改 conf/flink-conf.yaml;
可以通过:-D
-Dfs.overwrite-files=true -Dtaskmanager.network.numberOfBuffers=16368
如果使用的是 flink on yarn 方式,想切换回 standalone 模式的话,需要删除:/tmp/.yarn-properties-root,因为默认查找当前 yarn 集群中已有的 yarn-session 信息中的 jobmanager。三、Flink 运行架构1. Flink 程序结构
Flink 程序的基本构建块是流和转换(请注意,Flink 的 DataSet API 中使用的 DataSet 也是内部流 )。从概念上讲,流是(可能永无止境的)数据记录流,而转换是将一个或多个流作为一个或多个流的操作。输入,并产生一个或多个输出流。
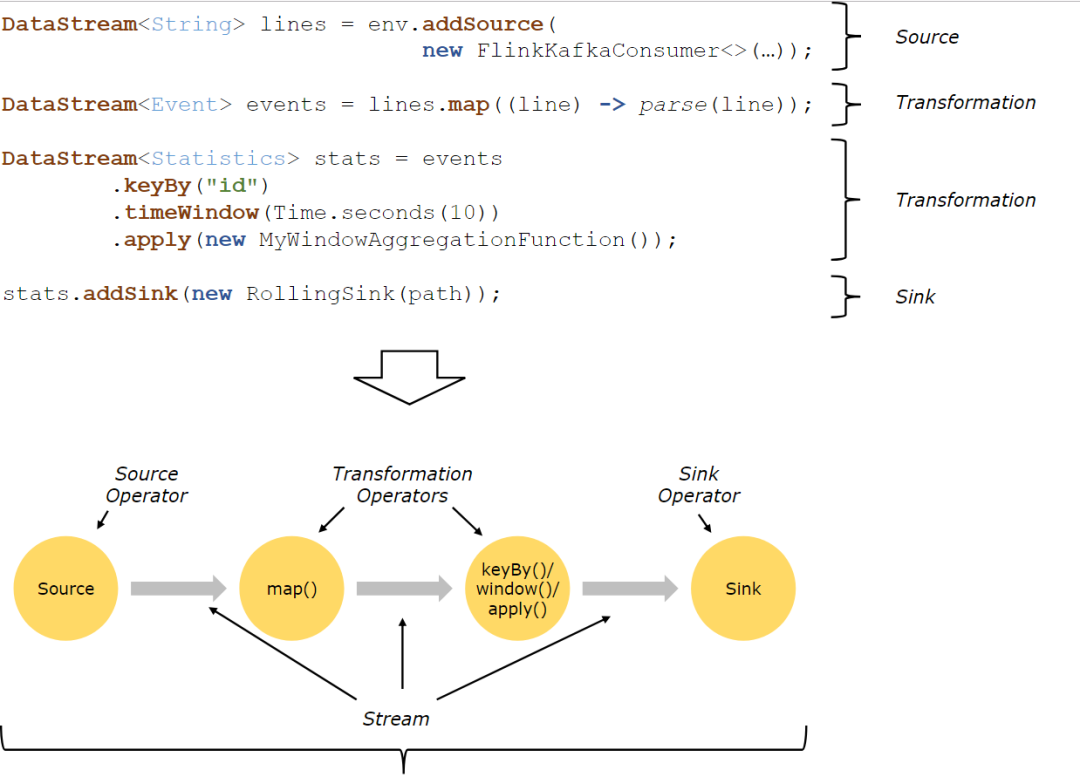
Flink 应用程序结构就是如上图所示:
Source: 数据源,Flink 在流处理和批处理上的 source 大概有 4 类:基于本地集合的 source、基于文件的 source、基于网络套接字的 source、自定义的 source。自定义的 source 常见的有 Apache kafka、RabbitMQ 等,当然你也可以定义自己的 source。
Transformation:数据转换的各种操作,有 Map / FlatMap / Filter / KeyBy / Reduce / Fold / Aggregations / Window / WindowAll / Union / Window join / Split / Select等,操作很多,可以将数据转换计算成你想要的数据。
Sink:接收器,Flink 将转换计算后的数据发送的地点 ,你可能需要存储下来,Flink 常见的 Sink 大概有如下几类:写入文件、打印出来、写入 socket 、自定义的 sink 。自定义的 sink 常见的有 Apache kafka、RabbitMQ、MySQL、ElasticSearch、Apache Cassandra、Hadoop FileSystem 等,同理你也可以定义自己的 sink。
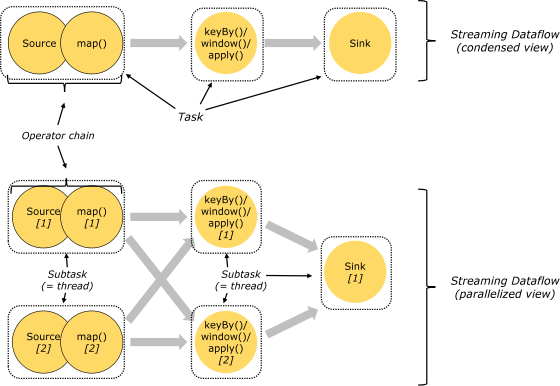
2. Flink 并行数据流
Flink 程序在执行的时候,会被映射成一个 Streaming Dataflow,一个 Streaming Dataflow 是由一组 Stream 和 Transformation Operator 组成的。在启动时从一个或多个 Source Operator 开始,结束于一个或多个 Sink Operator。
Flink 程序本质上是并行的和分布式的,在执行过程中,一个流(stream)包含一个或多个流分区,而每一个 operator 包含一个或多个 operator 子任务。操作子任务间彼此独立,在不同的线程中执行,甚至是在不同的机器或不同的容器上。operator 子任务的数量是这一特定 operator 的并行度。相同程序中的不同 operator 有不同级别的并行度。
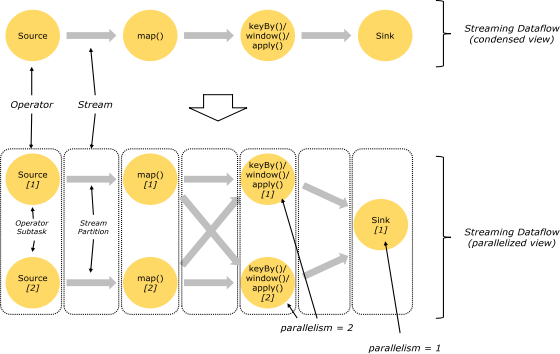
一个 Stream 可以被分成多个 Stream 的分区,也就是 Stream Partition。一个 Operator 也可以被分为多个 Operator Subtask。如上图中,Source 被分成 Source1 和 Source2,它们分别为 Source 的 Operator Subtask。每一个 Operator Subtask 都是在不同的线程当中独立执行的。一个 Operator 的并行度,就等于 Operator Subtask 的个数。上图 Source 的并行度为 2。而一个 Stream 的并行度就等于它生成的 Operator 的并行度。
数据在两个 operator 之间传递的时候有两种模式:
One to One 模式:两个 operator 用此模式传递的时候,会保持数据的分区数和数据的排序;如上图中的 Source1 到 Map1,它就保留的 Source 的分区特性,以及分区元素处理的有序性。
Redistributing (重新分配)模式:这种模式会改变数据的分区数;每个一个 operator subtask 会根据选择 transformation 把数据发送到不同的目标 subtasks,比如 keyBy()会通过 hashcode 重新分区,broadcast()和 rebalance()方法会随机重新分区;
3. Task 和 Operator chain
Flink的所有操作都称之为Operator,客户端在提交任务的时候会对Operator进行优化操作,能进行合并的Operator会被合并为一个Operator,合并后的Operator称为Operator chain,实际上就是一个执行链,每个执行链会在TaskManager上一个独立的线程中执行。
4. 任务调度与执行
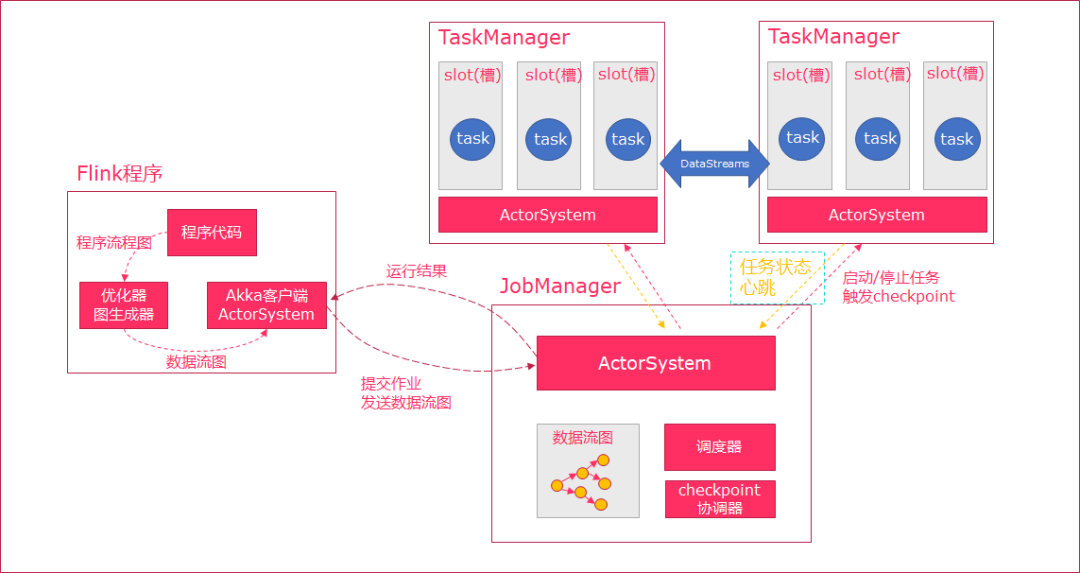
当Flink执行executor会自动根据程序代码生成DAG数据流图;
ActorSystem创建Actor将数据流图发送给JobManager中的Actor;
JobManager会不断接收TaskManager的心跳消息,从而可以获取到有效的TaskManager;
JobManager通过调度器在TaskManager中调度执行Task(在Flink中,最小的调度单元就是task,对应就是一个线程);
在程序运行过程中,task与task之间是可以进行数据传输的。
Job Client:
主要职责是提交任务, 提交后可以结束进程, 也可以等待结果返回;Job Client 不是 Flink 程序执行的内部部分,但它是任务执行的起点;Job Client 负责接受用户的程序代码,然后创建数据流,将数据流提交给 Job Manager 以便进一步执行。执行完成后,Job Client 将结果返回给用户。
JobManager:
主要职责是调度工作并协调任务做检查点;集群中至少要有一个 master,master 负责调度 task,协调checkpoints 和容错;高可用设置的话可以有多个 master,但要保证一个是 leader, 其他是standby;Job Manager 包含 Actor System、Scheduler、CheckPoint三个重要的组件;JobManager从客户端接收到任务以后, 首先生成优化过的执行计划, 再调度到TaskManager中执行。
TaskManager:
主要职责是从JobManager处接收任务, 并部署和启动任务, 接收上游的数据并处理;Task Manager 是在 JVM 中的一个或多个线程中执行任务的工作节点;TaskManager在创建之初就设置好了Slot, 每个Slot可以执行一个任务。5. 任务槽和槽共享
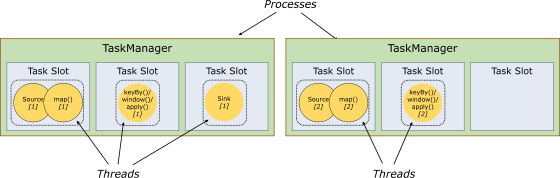
每个TaskManager是一个JVM的进程, 可以在不同的线程中执行一个或多个子任务。为了控制一个worker能接收多少个task。worker通过task slot来进行控制(一个worker至少有一个task slot)。
1) 任务槽
每个task slot表示TaskManager拥有资源的一个固定大小的子集。
flink将进程的内存进行了划分到多个slot中。
图中有2个TaskManager,每个TaskManager有3个slot的,每个slot占有1/3的内存。
内存被划分到不同的slot之后可以获得如下好处:
TaskManager最多能同时并发执行的任务是可以控制的,那就是3个,因为不能超过slot的数量。
slot有独占的内存空间,这样在一个TaskManager中可以运行多个不同的作业,作业之间不受影响。
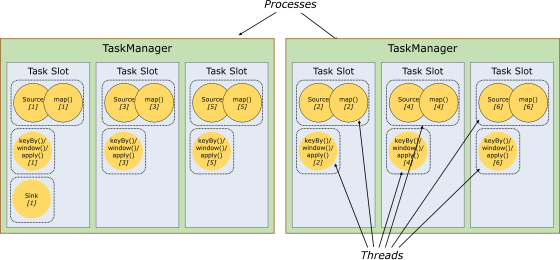
2) 槽共享
默认情况下,Flink允许子任务共享插槽,即使它们是不同任务的子任务,只要它们来自同一个作业。结果是一个槽可以保存作业的整个管道。允许插槽共享有两个主要好处:
只需计算Job中最高并行度(parallelism)的task slot,只要这个满足,其他的job也都能满足。
资源分配更加公平,如果有比较空闲的slot可以将更多的任务分配给它。图中若没有任务槽共享,负载不高的Source/Map等subtask将会占据许多资源,而负载较高的窗口subtask则会缺乏资源。
有了任务槽共享,可以将基本并行度(base parallelism)从2提升到6.提高了分槽资源的利用率。同时它还可以保障TaskManager给subtask的分配的slot方案更加公平。

 分享
分享








最新活动更多

先进LED照明系统,引领未来趋势新标杆")


-
10 阿里AI需要算一笔账了
- 1 GPT-6要来了,但AI行业早不跟 OpenAI玩了
- 2 产业丨算电协同+Token出海,中国电力与算力全球化双引擎
- 3 火爆的“Token经济学”,关乎你的钱包、职场和未来消费 | 人人能懂的产业报告
- 4 资本巨头纷纷抽身,为何中小投资者仍为AI狂热加码?
- 5 大厂财报中的AI图鉴:营收单列、玩杠杆、商业画饼
- 6 从百度到Meta,科技巨头的 AI 组织战,开打了
- 7 2026年3月,国内具身智能机器人企业融资汇总
- 8 华勤财报发布:收入规模破1700亿,利润增长近40%
- 9 宇树科技招股书透视:中外具身智能玩家生存竞速
- 10 大涨30%!智谱 AI 财报出炉:营收暴增132%,API 增长3倍,市值破 4000 亿



发表评论
登录
手机
验证码
手机/邮箱/用户名
密码
立即登录即可访问所有OFweek服务
还不是会员?免费注册
忘记密码其他方式
请输入评论内容...
请输入评论/评论长度6~500个字
暂无评论
暂无评论