









一文详解Flink知识体系
四、Flink 算子大全
Flink和Spark类似,也是一种一站式处理的框架;既可以进行批处理(DataSet),也可以进行实时处理(DataStream)。
所以下面将Flink的算子分为两大类:一类是DataSet,一类是DataStream。
DataSet 批处理算子一、Source算子1. fromCollection
fromCollection:从本地集合读取数据
例:
val env = ExecutionEnvironment.getExecutionEnvironment
val textDataSet: DataSet[String] = env.fromCollection(
List("1,张三", "2,李四", "3,王五", "4,赵六")
)
2. readTextFile
readTextFile:从文件中读取
val textDataSet: DataSet[String] = env.readTextFile("/data/a.txt")
3. readTextFile:遍历目录
readTextFile可以对一个文件目录内的所有文件,包括所有子目录中的所有文件的遍历访问方式
val parameters = new Configuration
// recursive.file.enumeration 开启递归
parameters.setBoolean("recursive.file.enumeration", true)
val file = env.readTextFile("/data").withParameters(parameters)
4. readTextFile:读取压缩文件
对于以下压缩类型,不需要指定任何额外的inputformat方法,flink可以自动识别并且解压。但是,压缩文件可能不会并行读取,可能是顺序读取的,这样可能会影响作业的可伸缩性。
压缩方法文件扩展名是否可并行读取DEFLATE.deflatenoGZip.gz .gzipnoBzip2.bz2noXZ.xznoval file = env.readTextFile("/data/file.gz")
二、Transform转换算子
因为Transform算子基于Source算子操作,所以首先构建Flink执行环境及Source算子,后续Transform算子操作基于此:
val env = ExecutionEnvironment.getExecutionEnvironment
val textDataSet: DataSet[String] = env.fromCollection(
List("张三,1", "李四,2", "王五,3", "张三,4")
)
1. map
将DataSet中的每一个元素转换为另外一个元素
// 使用map将List转换为一个Scala的样例类
case class User(name: String, id: String)
val userDataSet: DataSet[User] = textDataSet.map {
text =>
val fieldArr = text.split(",")
User(fieldArr(0), fieldArr(1))
}
userDataSet.print()
2. flatMap
将DataSet中的每一个元素转换为0...n个元素。
// 使用flatMap操作,将集合中的数据:
// 根据第一个元素,进行分组
// 根据第二个元素,进行聚合求值
val result = textDataSet.flatMap(line => line)
.groupBy(0) // 根据第一个元素,进行分组
.sum(1) // 根据第二个元素,进行聚合求值
result.print()
3. mapPartition
将一个分区中的元素转换为另一个元素
// 使用mapPartition操作,将List转换为一个scala的样例类
case class User(name: String, id: String)
val result: DataSet[User] = textDataSet.mapPartition(line => {
line.map(index => User(index._1, index._2))
})
result.print()
4. filter
过滤出来一些符合条件的元素,返回boolean值为true的元素
val source: DataSet[String] = env.fromElements("java", "scala", "java")
val filter:DataSet[String] = source.filter(line => line.contains("java"))//过滤出带java的数据
filter.print()
5. reduce
可以对一个dataset或者一个group来进行聚合计算,最终聚合成一个元素
// 使用 fromElements 构建数据源
val source = env.fromElements(("java", 1), ("scala", 1), ("java", 1))
// 使用map转换成DataSet元组
val mapData: DataSet[(String, Int)] = source.map(line => line)
// 根据首个元素分组
val groupData = mapData.groupBy(_._1)
// 使用reduce聚合
val reduceData = groupData.reduce((x, y) => (x._1, x._2 + y._2))
// 打印测试
reduceData.print()
6. reduceGroup
将一个dataset或者一个group聚合成一个或多个元素。
reduceGroup是reduce的一种优化方案;
它会先分组reduce,然后在做整体的reduce;这样做的好处就是可以减少网络IO
// 使用 fromElements 构建数据源
val source: DataSet[(String, Int)] = env.fromElements(("java", 1), ("scala", 1), ("java", 1))
// 根据首个元素分组
val groupData = source.groupBy(_._1)
// 使用reduceGroup聚合
val result: DataSet[(String, Int)] = groupData.reduceGroup {
(in: Iterator[(String, Int)], out: Collector[(String, Int)]) =>
val tuple = in.reduce((x, y) => (x._1, x._2 + y._2))
out.collect(tuple)
}
// 打印测试
result.print()
7. minBy和maxBy
选择具有最小值或最大值的元素
// 使用minBy操作,求List中每个人的最小值
// List("张三,1", "李四,2", "王五,3", "张三,4")
case class User(name: String, id: String)
// 将List转换为一个scala的样例类
val text: DataSet[User] = textDataSet.mapPartition(line => {
line.map(index => User(index._1, index._2))
})
val result = text
.groupBy(0) // 按照姓名分组
.minBy(1) // 每个人的最小值
8. Aggregate
在数据集上进行聚合求最值(最大值、最小值)
val data = new mutable.MutableList[(Int, String, Double)]
data.+=((1, "yuwen", 89.0))
data.+=((2, "shuxue", 92.2))
data.+=((3, "yuwen", 89.99))
// 使用 fromElements 构建数据源
val input: DataSet[(Int, String, Double)] = env.fromCollection(data)
// 使用group执行分组操作
val value = input.groupBy(1)
// 使用aggregate求最大值元素
.aggregate(Aggregations.MAX, 2)
// 打印测试
value.print()
Aggregate只能作用于元组上
注意:
要使用aggregate,只能使用字段索引名或索引名称来进行分组 groupBy(0) ,否则会报一下错误:
Exception in thread "main" java.lang.UnsupportedOperationException: Aggregate does not supportgrouping with KeySelector functions, yet.
9. distinct
去除重复的数据
// 数据源使用上一题的
// 使用distinct操作,根据科目去除集合中重复的元组数据
val value: DataSet[(Int, String, Double)] = input.distinct(1)
value.print()
10. first
取前N个数
input.first(2) // 取前两个数
11. join
将两个DataSet按照一定条件连接到一起,形成新的DataSet
// s1 和 s2 数据集格式如下:
// DataSet[(Int, String,String, Double)]
val joinData = s1.join(s2) // s1数据集 join s2数据集
.where(0).equalTo(0) { // join的条件
(s1, s2) => (s1._1, s1._2, s2._2, s1._3)
}
12. leftOuterJoin
左外连接,左边的Dataset中的每一个元素,去连接右边的元素
此外还有:
rightOuterJoin:右外连接,左边的Dataset中的每一个元素,去连接左边的元素
fullOuterJoin:全外连接,左右两边的元素,全部连接
下面以 leftOuterJoin 进行示例:
val data1 = ListBuffer[Tuple2[Int,String]]()
data1.append((1,"zhangsan"))
data1.append((2,"lisi"))
data1.append((3,"wangwu"))
data1.append((4,"zhaoliu"))
val data2 = ListBuffer[Tuple2[Int,String]]()
data2.append((1,"beijing"))
data2.append((2,"shanghai"))
data2.append((4,"guangzhou"))
val text1 = env.fromCollection(data1)
val text2 = env.fromCollection(data2)
text1.leftOuterJoin(text2).where(0).equalTo(0).apply((first,second)=>{
if(second==null){
(first._1,first._2,"null")
}else{
(first._1,first._2,second._2)
}
}).print()
13. cross
交叉操作,通过形成这个数据集和其他数据集的笛卡尔积,创建一个新的数据集
和join类似,但是这种交叉操作会产生笛卡尔积,在数据比较大的时候,是非常消耗内存的操作
val cross = input1.cross(input2){
(input1 , input2) => (input1._1,input1._2,input1._3,input2._2)
}
cross.print()
14. union
联合操作,创建包含来自该数据集和其他数据集的元素的新数据集,不会去重
val unionData: DataSet[String] = elements1.union(elements2).union(elements3)
// 去除重复数据
val value = unionData.distinct(line => line)
15. rebalance
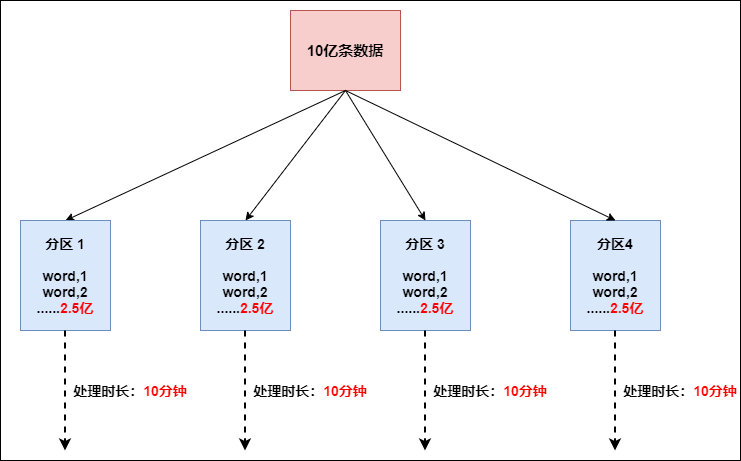
Flink也有数据倾斜的时候,比如当前有数据量大概10亿条数据需要处理,在处理过程中可能会发生如图所示的状况:

这个时候本来总体数据量只需要10分钟解决的问题,出现了数据倾斜,机器1上的任务需要4个小时才能完成,那么其他3台机器执行完毕也要等待机器1执行完毕后才算整体将任务完成;所以在实际的工作中,出现这种情况比较好的解决方案就是接下来要介绍的—rebalance(内部使用round robin方法将数据均匀打散。这对于数据倾斜时是很好的选择。)
// 使用rebalance操作,避免数据倾斜
val rebalance = filterData.rebalance()
16. partitionByHash
按照指定的key进行hash分区
val data = new mutable.MutableList[(Int, Long, String)]
data.+=((1, 1L, "Hi"))
data.+=((2, 2L, "Hello"))
data.+=((3, 2L, "Hello world"))
val collection = env.fromCollection(data)
val unique = collection.partitionByHash(1).mapPartition{
line =>
line.map(x => (x._1 , x._2 , x._3))
}
unique.writeAsText("hashPartition", WriteMode.NO_OVERWRITE)
env.execute()
17. partitionByRange
根据指定的key对数据集进行范围分区
val data = new mutable.MutableList[(Int, Long, String)]
data.+=((1, 1L, "Hi"))
data.+=((2, 2L, "Hello"))
data.+=((3, 2L, "Hello world"))
data.+=((4, 3L, "Hello world, how are you?"))
val collection = env.fromCollection(data)
val unique = collection.partitionByRange(x => x._1).mapPartition(line => line.map{
x=>
(x._1 , x._2 , x._3)
})
unique.writeAsText("rangePartition", WriteMode.OVERWRITE)
env.execute()
18. sortPartition
根据指定的字段值进行分区的排序
val data = new mutable.MutableList[(Int, Long, String)]
data.+=((1, 1L, "Hi"))
data.+=((2, 2L, "Hello"))
data.+=((3, 2L, "Hello world"))
data.+=((4, 3L, "Hello world, how are you?"))
val ds = env.fromCollection(data)
val result = ds
.map { x => x }.setParallelism(2)
.sortPartition(1, Order.DESCENDING)//第一个参数代表按照哪个字段进行分区
.mapPartition(line => line)
.collect()
println(result)
三、Sink算子1. collect
将数据输出到本地集合
result.collect()
2. writeAsText
将数据输出到文件
Flink支持多种存储设备上的文件,包括本地文件,hdfs文件等
Flink支持多种文件的存储格式,包括text文件,CSV文件等
// 将数据写入本地文件
result.writeAsText("/data/a", WriteMode.OVERWRITE)
// 将数据写入HDFS
result.writeAsText("hdfs://node01:9000/data/a", WriteMode.OVERWRITE)
DataStream流处理算子
和DataSet一样,DataStream也包括一系列的Transformation操作
一、Source算子
Flink可以使用 StreamExecutionEnvironment.addSource(source) 来为我们的程序添加数据来源。
Flink 已经提供了若干实现好了的 source functions,当然我们也可以通过实现 SourceFunction 来自定义非并行的source或者实现 ParallelSourceFunction 接口或者扩展 RichParallelSourceFunction 来自定义并行的 source。
Flink在流处理上的source和在批处理上的source基本一致。大致有4大类:
基于本地集合的source(Collection-based-source)基于文件的source(File-based-source)- 读取文本文件,即符合 TextInputFormat 规范的文件,并将其作为字符串返回基于网络套接字的source(Socket-based-source)- 从 socket 读取。元素可以用分隔符切分。自定义的source(Custom-source)
下面使用addSource将Kafka数据写入Flink为例:
如果需要外部数据源对接,可使用addSource,如将Kafka数据写入Flink,先引入依赖:
将Kafka数据写入Flink:
val properties = new Properties()
properties.setProperty("bootstrap.servers", "localhost:9092")
properties.setProperty("group.id", "consumer-group")
properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer")
properties.setProperty("auto.offset.reset", "latest")
val source = env.addSource(new FlinkKafkaConsumer011[String]("sensor", new SimpleStringSchema(), properties))
基于网络套接字的:
val source = env.socketTextStream("IP", PORT)
二、Transform转换算子1. map
将DataSet中的每一个元素转换为另外一个元素
dataStream.map { x => x * 2 }
2. FlatMap
采用一个数据元并生成零个,一个或多个数据元。将句子分割为单词的flatmap函数
dataStream.flatMap { str => str.split(" ") }
3. Filter
计算每个数据元的布尔函数,并保存函数返回true的数据元。过滤掉零值的过滤器
dataStream.filter { _ != 0 }
4. KeyBy
逻辑上将流分区为不相交的分区。具有相同Keys的所有记录都分配给同一分区。在内部,keyBy()是使用散列分区实现的。指定键有不同的方法。
此转换返回KeyedStream,其中包括使用被Keys化状态所需的KeyedStream。
dataStream.keyBy(0)
5. Reduce
被Keys化数据流上的“滚动”Reduce。将当前数据元与最后一个Reduce的值组合并发出新值
keyedStream.reduce { _ + _ }
6. Fold
具有初始值的被Keys化数据流上的“滚动”折叠。将当前数据元与最后折叠的值组合并发出新值
val result: DataStream[String] = keyedStream.fold("start")((str, i) => { str + "-" + i })
// 解释:当上述代码应用于序列(1,2,3,4,5)时,输出结果“start-1”,“start-1-2”,“start-1-2-3”,...
7. Aggregations
在被Keys化数据流上滚动聚合。min和minBy之间的差异是min返回最小值,而minBy返回该字段中具有最小值的数据元(max和maxBy相同)。
keyedStream.sum(0);
keyedStream.min(0);
keyedStream.max(0);
keyedStream.minBy(0);
keyedStream.maxBy(0);
8. Window
可以在已经分区的KeyedStream上定义Windows。Windows根据某些特征(例如,在最后5秒内到达的数据)对每个Keys中的数据进行分组。这里不再对窗口进行详解,有关窗口的完整说明,请查看这篇文章:Flink 中极其重要的 Time 与 Window 详细解析
dataStream.keyBy(0).window(TumblingEventTimeWindows.of(Time.seconds(5)));
9. WindowAll
Windows可以在常规DataStream上定义。Windows根据某些特征(例如,在最后5秒内到达的数据)对所有流事件进行分组。
注意:在许多情况下,这是非并行转换。所有记录将收集在windowAll 算子的一个任务中。
dataStream.windowAll(TumblingEventTimeWindows.of(Time.seconds(5)))
10. Window Apply
将一般函数应用于整个窗口。
注意:如果您正在使用windowAll转换,则需要使用AllWindowFunction。
下面是一个手动求和窗口数据元的函数
windowedStream.apply { WindowFunction }
allWindowedStream.apply { AllWindowFunction }
11. Window Reduce
将函数缩减函数应用于窗口并返回缩小的值
windowedStream.reduce { _ + _ }
12. Window Fold
将函数折叠函数应用于窗口并返回折叠值
val result: DataStream[String] = windowedStream.fold("start", (str, i) => { str + "-" + i })
// 上述代码应用于序列(1,2,3,4,5)时,将序列折叠为字符串“start-1-2-3-4-5”
13. Union
两个或多个数据流的联合,创建包含来自所有流的所有数据元的新流。注意:如果将数据流与自身联合,则会在结果流中获取两次数据元
dataStream.union(otherStream1, otherStream2, ...)
14. Window Join
在给定Keys和公共窗口上连接两个数据流
dataStream.join(otherStream)
.where(
在给定的时间间隔内使用公共Keys关联两个被Key化的数据流的两个数据元e1和e2,以便e1.timestamp + lowerBound <= e2.timestamp <= e1.timestamp + upperBound
am.intervalJoin(otherKeyedStream)
.between(Time.milliseconds(-2), Time.milliseconds(2))
.upperBoundExclusive(true)
.lowerBoundExclusive(true)
.process(new IntervalJoinFunction() {...})
16. Window CoGroup
在给定Keys和公共窗口上对两个数据流进行Cogroup
dataStream.coGroup(otherStream)
.where(0).equalTo(1)
.window(TumblingEventTimeWindows.of(Time.seconds(3)))
.apply (new CoGroupFunction () {...})
17. Connect
“连接”两个保存其类型的数据流。连接允许两个流之间的共享状态
DataStream
类似于连接数据流上的map和flatMap
connectedStreams.map(
(_ : Int) => true,
(_ : String) => false)connectedStreams.flatMap(
(_ : Int) => true,
(_ : String) => false)
19. Split
根据某些标准将流拆分为两个或更多个流
val split = someDataStream.split(
(num: Int) =>
(num % 2) match {
case 0 => List("even")
case 1 => List("odd")
})
20. Select
从拆分流中选择一个或多个流
SplitStream
支持将数据输出到:
本地文件(参考批处理)本地集合(参考批处理)HDFS(参考批处理)
除此之外,还支持:
sink到kafkasink到mysqlsink到redis
下面以sink到kafka为例:
val sinkTopic = "test"
//样例类
case class Student(id: Int, name: String, addr: String, sex: String)
val mapper: ObjectMapper = new ObjectMapper()
//将对象转换成字符串
def toJsonString(T: Object): String = {
mapper.registerModule(DefaultScalaModule)
mapper.writeValueAsString(T)
}
def main(args: Array[String]): Unit = {
//1.创建流执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.准备数据
val dataStream: DataStream[Student] = env.fromElements(
Student(8, "xiaoming", "beijing biejing", "female")
)
//将student转换成字符串
val studentStream: DataStream[String] = dataStream.map(student =>
toJsonString(student) // 这里需要显示SerializerFeature中的某一个,否则会报同时匹配两个方法的错误
)
//studentStream.print()
val prop = new Properties()
prop.setProperty("bootstrap.servers", "node01:9092")
val myProducer = new FlinkKafkaProducer011[String](sinkTopic, new KeyedSerializationSchemaWrapper[String](new SimpleStringSchema()), prop)
studentStream.addSink(myProducer)
studentStream.print()
env.execute("Flink add sink")
}
五、流处理中的Time与Window
Flink 是流式的、实时的 计算引擎。
上面一句话就有两个概念,一个是流式,一个是实时。
流式:就是数据源源不断的流进来,也就是数据没有边界,但是我们计算的时候必须在一个有边界的范围内进行,所以这里面就有一个问题,边界怎么确定?无非就两种方式,根据时间段或者数据量进行确定,根据时间段就是每隔多长时间就划分一个边界,根据数据量就是每来多少条数据划分一个边界,Flink 中就是这么划分边界的,本文会详细讲解。
实时:就是数据发送过来之后立马就进行相关的计算,然后将结果输出。这里的计算有两种:
一种是只有边界内的数据进行计算,这种好理解,比如统计每个用户最近五分钟内浏览的新闻数量,就可以取最近五分钟内的所有数据,然后根据每个用户分组,统计新闻的总数。
另一种是边界内数据与外部数据进行关联计算,比如:统计最近五分钟内浏览新闻的用户都是来自哪些地区,这种就需要将五分钟内浏览新闻的用户信息与 hive 中的地区维表进行关联,然后在进行相关计算。
本节所讲的 Flink 内容就是围绕以上概念进行详细剖析的!
1. Time
在Flink中,如果以时间段划分边界的话,那么时间就是一个极其重要的字段。
Flink中的时间有三种类型,如下图所示:
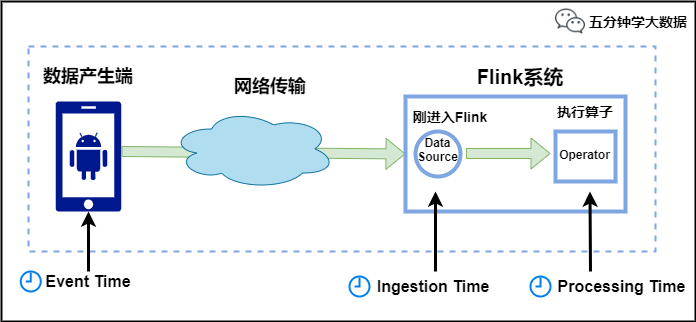
Event Time:是事件创建的时间。它通常由事件中的时间戳描述,例如采集的日志数据中,每一条日志都会记录自己的生成时间,Flink通过时间戳分配器访问事件时间戳。
Ingestion Time:是数据进入Flink的时间。
Processing Time:是每一个执行基于时间操作的算子的本地系统时间,与机器相关,默认的时间属性就是Processing Time。
例如,一条日志进入Flink的时间为2021-01-22 10:00:00.123,到达Window的系统时间为2021-01-22 10:00:01.234,日志的内容如下:
2021-01-06 18:37:15.624 INFO Fail over to rm2
对于业务来说,要统计1min内的故障日志个数,哪个时间是最有意义的?—— eventTime,因为我们要根据日志的生成时间进行统计。
2. Window
Window,即窗口,我们前面一直提到的边界就是这里的Window(窗口)。
官方解释:流式计算是一种被设计用于处理无限数据集的数据处理引擎,而无限数据集是指一种不断增长的本质上无限的数据集,而window是一种切割无限数据为有限块进行处理的手段。
所以Window是无限数据流处理的核心,Window将一个无限的stream拆分成有限大小的”buckets”桶,我们可以在这些桶上做计算操作。
Window类型
本文刚开始提到,划分窗口就两种方式:
根据时间进行截取(time-driven-window),比如每1分钟统计一次或每10分钟统计一次。根据数据进行截取(data-driven-window),比如每5个数据统计一次或每50个数据统计一次。
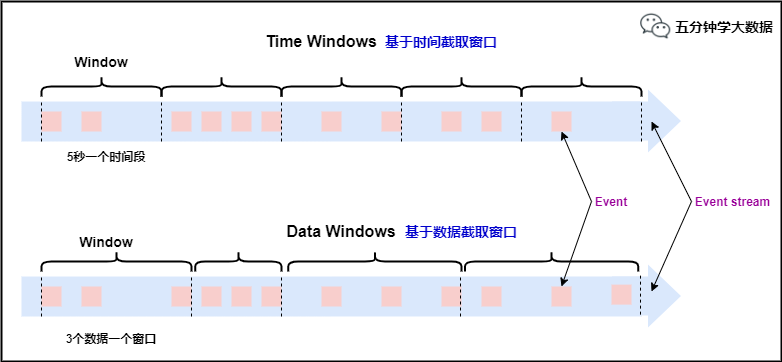
窗口类型
对于TimeWindow(根据时间划分窗口), 可以根据窗口实现原理的不同分成三类:滚动窗口(Tumbling Window)、滑动窗口(Sliding Window)和会话窗口(Session Window)。
滚动窗口(Tumbling Windows)
将数据依据固定的窗口长度对数据进行切片。
特点:时间对齐,窗口长度固定,没有重叠。
滚动窗口分配器将每个元素分配到一个指定窗口大小的窗口中,滚动窗口有一个固定的大小,并且不会出现重叠。
例如:如果你指定了一个5分钟大小的滚动窗口,窗口的创建如下图所示:

滚动窗口
适用场景:适合做BI统计等(做每个时间段的聚合计算)。
滑动窗口(Sliding Windows)
滑动窗口是固定窗口的更广义的一种形式,滑动窗口由固定的窗口长度和滑动间隔组成。
特点:时间对齐,窗口长度固定,有重叠。
滑动窗口分配器将元素分配到固定长度的窗口中,与滚动窗口类似,窗口的大小由窗口大小参数来配置,另一个窗口滑动参数控制滑动窗口开始的频率。因此,滑动窗口如果滑动参数小于窗口大小的话,窗口是可以重叠的,在这种情况下元素会被分配到多个窗口中。
例如,你有10分钟的窗口和5分钟的滑动,那么每个窗口中5分钟的窗口里包含着上个10分钟产生的数据,如下图所示:
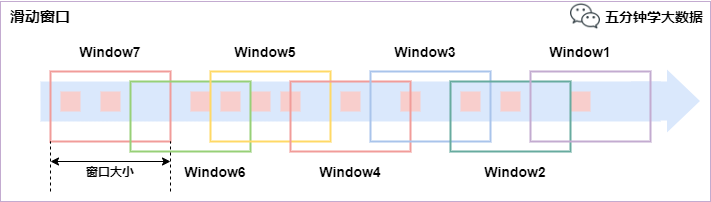
滑动窗口
适用场景:对最近一个时间段内的统计(求某接口最近5min的失败率来决定是否要报警)。
会话窗口(Session Windows)
由一系列事件组合一个指定时间长度的timeout间隙组成,类似于web应用的session,也就是一段时间没有接收到新数据就会生成新的窗口。
特点:时间无对齐。
session窗口分配器通过session活动来对元素进行分组,session窗口跟滚动窗口和滑动窗口相比,不会有重叠和固定的开始时间和结束时间的情况,相反,当它在一个固定的时间周期内不再收到元素,即非活动间隔产生,那个这个窗口就会关闭。一个session窗口通过一个session间隔来配置,这个session间隔定义了非活跃周期的长度,当这个非活跃周期产生,那么当前的session将关闭并且后续的元素将被分配到新的session窗口中去。
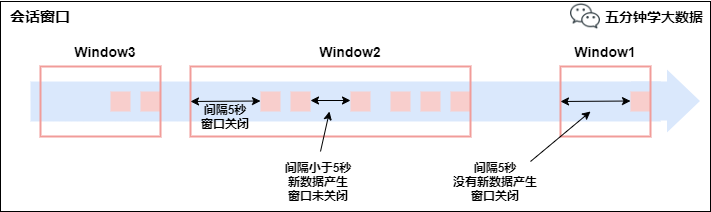
会话窗口3. Window API1) TimeWindow
TimeWindow是将指定时间范围内的所有数据组成一个window,一次对一个window里面的所有数据进行计算(就是本文开头说的对一个边界内的数据进行计算)。
我们以 红绿灯路口通过的汽车数量 为例子:
红绿灯路口会有汽车通过,一共会有多少汽车通过,无法计算。因为车流源源不断,计算没有边界。
所以我们统计每15秒钟通过红路灯的汽车数量,如第一个15秒为2辆,第二个15秒为3辆,第三个15秒为1辆 ...
tumbling-time-window (无重叠数据)
我们使用 Linux 中的 nc 命令模拟数据的发送方
1.开启发送端口,端口号为9999
nc -lk 9999
2.发送内容(key 代表不同的路口,value 代表每次通过的车辆)
一次发送一行,发送的时间间隔代表汽车经过的时间间隔
9,3
9,2
9,7
4,9
2,6
1,5
2,3
5,7
5,4
Flink 进行采集数据并计算:
object Window {
def main(args: Array[String]): Unit = {
//TODO time-window
//1.创建运行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.定义数据流来源
val text = env.socketTextStream("localhost", 9999)
//3.转换数据格式,text->CarWc
case class CarWc(sensorId: Int, carCnt: Int)
val ds1: DataStream[CarWc] = text.map {
line => {
val tokens = line.split(",")
CarWc(tokens(0).trim.toInt, tokens(1).trim.toInt)
}
}
//4.执行统计操作,每个sensorId一个tumbling窗口,窗口的大小为5秒
//也就是说,每5秒钟统计一次,在这过去的5秒钟内,各个路口通过红绿灯汽车的数量。
val ds2: DataStream[CarWc] = ds1
.keyBy("sensorId")
.timeWindow(Time.seconds(5))
.sum("carCnt")
//5.显示统计结果
ds2.print()
//6.触发流计算
env.execute(this.getClass.getName)
}
}
我们发送的数据并没有指定时间字段,所以Flink使用的是默认的 Processing Time,也就是Flink系统处理数据时的时间。
sliding-time-window (有重叠数据)//1.创建运行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.定义数据流来源
val text = env.socketTextStream("localhost", 9999)
//3.转换数据格式,text->CarWc
case class CarWc(sensorId: Int, carCnt: Int)
val ds1: DataStream[CarWc] = text.map {
line => {
val tokens = line.split(",")
CarWc(tokens(0).trim.toInt, tokens(1).trim.toInt)
}
}
//4.执行统计操作,每个sensorId一个sliding窗口,窗口时间10秒,滑动时间5秒
//也就是说,每5秒钟统计一次,在这过去的10秒钟内,各个路口通过红绿灯汽车的数量。
val ds2: DataStream[CarWc] = ds1
.keyBy("sensorId")
.timeWindow(Time.seconds(10), Time.seconds(5))
.sum("carCnt")
//5.显示统计结果
ds2.print()
//6.触发流计算
env.execute(this.getClass.getName)
2) CountWindow
CountWindow根据窗口中相同key元素的数量来触发执行,执行时只计算元素数量达到窗口大小的key对应的结果。
注意:CountWindow的window_size指的是相同Key的元素的个数,不是输入的所有元素的总数。
tumbling-count-window (无重叠数据)//1.创建运行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.定义数据流来源
val text = env.socketTextStream("localhost", 9999)
//3.转换数据格式,text->CarWc
case class CarWc(sensorId: Int, carCnt: Int)
val ds1: DataStream[CarWc] = text.map {
(f) => {
val tokens = f.split(",")
CarWc(tokens(0).trim.toInt, tokens(1).trim.toInt)
}
}
//4.执行统计操作,每个sensorId一个tumbling窗口,窗口的大小为5
//按照key进行收集,对应的key出现的次数达到5次作为一个结果
val ds2: DataStream[CarWc] = ds1
.keyBy("sensorId")
.countWindow(5)
.sum("carCnt")
//5.显示统计结果
ds2.print()
//6.触发流计算
env.execute(this.getClass.getName)
sliding-count-window (有重叠数据)
同样也是窗口长度和滑动窗口的操作:窗口长度是5,滑动长度是3
//1.创建运行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.定义数据流来源
val text = env.socketTextStream("localhost", 9999)
//3.转换数据格式,text->CarWc
case class CarWc(sensorId: Int, carCnt: Int)
val ds1: DataStream[CarWc] = text.map {
(f) => {
val tokens = f.split(",")
CarWc(tokens(0).trim.toInt, tokens(1).trim.toInt)
}
}
//4.执行统计操作,每个sensorId一个sliding窗口,窗口大小3条数据,窗口滑动为3条数据
//也就是说,每个路口分别统计,收到关于它的3条消息时统计在最近5条消息中,各自路口通过的汽车数量
val ds2: DataStream[CarWc] = ds1
.keyBy("sensorId")
.countWindow(5, 3)
.sum("carCnt")
//5.显示统计结果
ds2.print()
//6.触发流计算
env.execute(this.getClass.getName)
Window 总结
flink支持两种划分窗口的方式(time和count)
如果根据时间划分窗口,那么它就是一个time-window
如果根据数据划分窗口,那么它就是一个count-window
flink支持窗口的两个重要属性(size和interval)
如果size=interval,那么就会形成tumbling-window(无重叠数据)
如果size>interval,那么就会形成sliding-window(有重叠数据)
如果size
通过组合可以得出四种基本窗口
time-tumbling-window 无重叠数据的时间窗口,设置方式举例:timeWindow(Time.seconds(5))
time-sliding-window 有重叠数据的时间窗口,设置方式举例:timeWindow(Time.seconds(5), Time.seconds(3))
count-tumbling-window无重叠数据的数量窗口,设置方式举例:countWindow(5)
count-sliding-window 有重叠数据的数量窗口,设置方式举例:countWindow(5,3)
3) Window Reduce
WindowedStream → DataStream:给window赋一个reduce功能的函数,并返回一个聚合的结果。
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
object StreamWindowReduce {
def main(args: Array[String]): Unit = {
// 获取执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 创建SocketSource
val stream = env.socketTextStream("node01", 9999)
// 对stream进行处理并按key聚合
val streamKeyBy = stream.map(item => (item, 1)).keyBy(0)
// 引入时间窗口
val streamWindow = streamKeyBy.timeWindow(Time.seconds(5))
// 执行聚合操作
val streamReduce = streamWindow.reduce(
(item1, item2) => (item1._1, item1._2 + item2._2)
)
// 将聚合数据写入文件
streamReduce.print()
// 执行程序
env.execute("TumblingWindow")
}
}
4) Window Apply
apply方法可以进行一些自定义处理,通过匿名内部类的方法来实现。当有一些复杂计算时使用。
用法
实现一个 WindowFunction 类指定该类的泛型为 [输入数据类型, 输出数据类型, keyBy中使用分组字段的类型, 窗口类型]
示例:使用apply方法来实现单词统计
步骤:
获取流处理运行环境构建socket流数据源,并指定IP地址和端口号对接收到的数据转换成单词元组使用 keyBy 进行分流(分组)使用 timeWinodw 指定窗口的长度(每3秒计算一次)实现一个WindowFunction匿名内部类apply方法中实现聚合计算使用Collector.collect收集数据
核心代码如下:
//1. 获取流处理运行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2. 构建socket流数据源,并指定IP地址和端口号
val textDataStream = env.socketTextStream("node01", 9999).flatMap(_.split(" "))
//3. 对接收到的数据转换成单词元组
val wordDataStream = textDataStream.map(_->1)
//4. 使用 keyBy 进行分流(分组)
val groupedDataStream: KeyedStream[(String, Int), String] = wordDataStream.keyBy(_._1)
//5. 使用 timeWinodw 指定窗口的长度(每3秒计算一次)
val windowDataStream: WindowedStream[(String, Int), String, TimeWindow] = groupedDataStream.timeWindow(Time.seconds(3))
//6. 实现一个WindowFunction匿名内部类
val reduceDatStream: DataStream[(String, Int)] = windowDataStream.apply(new RichWindowFunction[(String, Int), (String, Int), String, TimeWindow] {
//在apply方法中实现数据的聚合
override def apply(key: String, window: TimeWindow, input: Iterable[(String, Int)], out: Collector[(String, Int)]): Unit = {
println("hello world")
val tuple = input.reduce((t1, t2) => {
(t1._1, t1._2 + t2._2)
})
//将要返回的数据收集起来,发送回去
out.collect(tuple)
}
})
reduceDatStream.print()
env.execute()
5) Window Fold
WindowedStream → DataStream:给窗口赋一个fold功能的函数,并返回一个fold后的结果。
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
object StreamWindowFold {
def main(args: Array[String]): Unit = {
// 获取执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 创建SocketSource
val stream = env.socketTextStream("node01", 9999,'',3)
// 对stream进行处理并按key聚合
val streamKeyBy = stream.map(item => (item, 1)).keyBy(0)
// 引入滚动窗口
val streamWindow = streamKeyBy.timeWindow(Time.seconds(5))
// 执行fold操作
val streamFold = streamWindow.fold(100){
(begin, item) =>
begin + item._2
}
// 将聚合数据写入文件
streamFold.print()
// 执行程序
env.execute("TumblingWindow")
}
}
6) Aggregation on Window
WindowedStream → DataStream:对一个window内的所有元素做聚合操作。min和 minBy的区别是min返回的是最小值,而minBy返回的是包含最小值字段的元素(同样的原理适用于 max 和 maxBy)。
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.api.scala._
object StreamWindowAggregation {
def main(args: Array[String]): Unit = {
// 获取执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 创建SocketSource
val stream = env.socketTextStream("node01", 9999)
// 对stream进行处理并按key聚合
val streamKeyBy = stream.map(item => (item.split(" ")(0), item.split(" ")(1))).keyBy(0)
// 引入滚动窗口
val streamWindow = streamKeyBy.timeWindow(Time.seconds(5))
// 执行聚合操作
val streamMax = streamWindow.max(1)
// 将聚合数据写入文件
streamMax.print()
// 执行程序
env.execute("TumblingWindow")
}
}
4. EventTime与Window1) EventTime的引入与现实世界中的时间是不一致的,在flink中被划分为事件时间,提取时间,处理时间三种。如果以EventTime为基准来定义时间窗口那将形成EventTimeWindow,要求消息本身就应该携带EventTime如果以IngesingtTime为基准来定义时间窗口那将形成IngestingTimeWindow,以source的systemTime为准。如果以ProcessingTime基准来定义时间窗口那将形成ProcessingTimeWindow,以operator的systemTime为准。
在Flink的流式处理中,绝大部分的业务都会使用eventTime,一般只在eventTime无法使用时,才会被迫使用ProcessingTime或者IngestionTime。
如果要使用EventTime,那么需要引入EventTime的时间属性,引入方式如下所示:
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 从调用时刻开始给env创建的每一个stream追加时间特征
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
2) Watermark
我们知道,流处理从事件产生,到流经 source,再到 operator,中间是有一个过程和时间的,虽然大部分情况下,流到 operator 的数据都是按照事件产生的时间顺序来的,但是也不排除由于网络、背压等原因,导致乱序的产生,所谓乱序,就是指 Flink 接收到的事件的先后顺序不是严格按照事件的 Event Time 顺序排列的,所以 Flink 最初设计的时候,就考虑到了网络延迟,网络乱序等问题,所以提出了一个抽象概念:水印(WaterMark);
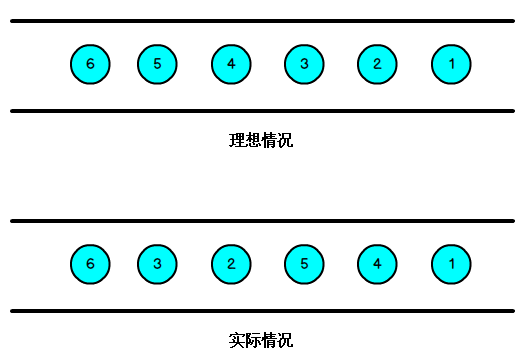
如上图所示,就出现一个问题,一旦出现乱序,如果只根据 EventTime 决定 Window 的运行,我们不能明确数据是否全部到位,但又不能无限期的等下去,此时必须要有个机制来保证一个特定的时间后,必须触发 Window 去进行计算了,这个特别的机制,就是 Watermark。
Watermark 是用于处理乱序事件的,而正确的处理乱序事件,通常用 Watermark 机制结合 Window 来实现。
数据流中的 Watermark 用于表示 timestamp 小于 Watermark 的数据,都已经到达了,因此,Window 的执行也是由 Watermark 触发的。
Watermark 可以理解成一个延迟触发机制,我们可以设置 Watermark 的延时时长 t,每次系统会校验已经到达的数据中最大的 maxEventTime,然后认定 EventTime 小于 maxEventTime - t 的所有数据都已经到达,如果有窗口的停止时间等于 maxEventTime – t,那么这个窗口被触发执行。
有序流的Watermarker如下图所示:(Watermark设置为0)

有序数据的Watermark
乱序流的Watermarker如下图所示:(Watermark设置为2)

无序数据的Watermark
当 Flink 接收到每一条数据时,都会产生一条 Watermark,这条 Watermark 就等于当前所有到达数据中的 maxEventTime - 延迟时长,也就是说,Watermark 是由数据携带的,一旦数据携带的 Watermark 比当前未触发的窗口的停止时间要晚,那么就会触发相应窗口的执行。由于 Watermark 是由数据携带的,因此,如果运行过程中无法获取新的数据,那么没有被触发的窗口将永远都不被触发。
上图中,我们设置的允许最大延迟到达时间为2s,所以时间戳为7s的事件对应的Watermark是5s,时间戳为12s的事件的Watermark是10s,如果我们的窗口1是1s~5s,窗口2是6s~10s,那么时间戳为7s的事件到达时的Watermarker恰好触发窗口1,时间戳为12s的事件到达时的Watermark恰好触发窗口2。
3) Flink对于迟到数据的处理
waterMark和Window机制解决了流式数据的乱序问题,对于因为延迟而顺序有误的数据,可以根据eventTime进行业务处理,于延迟的数据Flink也有自己的解决办法,主要的办法是给定一个允许延迟的时间,在该时间范围内仍可以接受处理延迟数据。
设置允许延迟的时间是通过 allowedLateness(lateness: Time) 设置
保存延迟数据则是通过 sideOutputLateData(outputTag: OutputTag[T]) 保存
获取延迟数据是通过 DataStream.getSideOutput(tag: OutputTag[X]) 获取
具体的用法如下:
allowedLateness(lateness: Time)
def allowedLateness(lateness: Time): WindowedStream[T, K, W] = {
javaStream.allowedLateness(lateness)
this
}
该方法传入一个Time值,设置允许数据迟到的时间,这个时间和 WaterMark 中的时间概念不同。再来回顾一下:
WaterMark=数据的事件时间-允许乱序时间值
随着新数据的到来,waterMark的值会更新为最新数据事件时间-允许乱序时间值,但是如果这时候来了一条历史数据,waterMark值则不会更新。总的来说,waterMark是为了能接收到尽可能多的乱序数据。
那这里的Time值,主要是为了等待迟到的数据,在一定时间范围内,如果属于该窗口的数据到来,仍会进行计算,后面会对计算方式仔细说明
注意:该方法只针对于基于event-time的窗口,如果是基于processing-time,并且指定了非零的time值则会抛出异常。
sideOutputLateData(outputTag: OutputTag[T])
def sideOutputLateData(outputTag: OutputTag[T]): WindowedStream[T, K, W] = {
javaStream.sideOutputLateData(outputTag)
this
}
该方法是将迟来的数据保存至给定的outputTag参数,而OutputTag则是用来标记延迟数据的一个对象。
DataStream.getSideOutput(tag: OutputTag[X])
通过window等操作返回的DataStream调用该方法,传入标记延迟数据的对象来获取延迟的数据。
对延迟数据的理解
延迟数据是指:
在当前窗口【假设窗口范围为10-15】已经计算之后,又来了一个属于该窗口的数据【假设事件时间为13】,这时候仍会触发 Window 操作,这种数据就称为延迟数据。
那么问题来了,延迟时间怎么计算呢?
假设窗口范围为10-15,延迟时间为2s,则只要 WaterMark<15+2,并且属于该窗口,就能触发 Window 操作。而如果来了一条数据使得 WaterMark>=15+2,10-15这个窗口就不能再触发 Window 操作,即使新来的数据的 Event Time 属于这个窗口时间内 。

 分享
分享








最新活动更多

先进LED照明系统,引领未来趋势新标杆")


-
10 阿里AI需要算一笔账了
- 1 GPT-6要来了,但AI行业早不跟 OpenAI玩了
- 2 火爆的“Token经济学”,关乎你的钱包、职场和未来消费 | 人人能懂的产业报告
- 3 资本巨头纷纷抽身,为何中小投资者仍为AI狂热加码?
- 4 大厂财报中的AI图鉴:营收单列、玩杠杆、商业画饼
- 5 从百度到Meta,科技巨头的 AI 组织战,开打了
- 6 2026年3月,国内具身智能机器人企业融资汇总
- 7 华勤财报发布:收入规模破1700亿,利润增长近40%
- 8 宇树科技招股书透视:中外具身智能玩家生存竞速
- 9 大涨30%!智谱 AI 财报出炉:营收暴增132%,API 增长3倍,市值破 4000 亿
- 10 谷歌Gemma 4遭破解!实测:伪造支票、找盗版电影,有求必应



发表评论
登录
手机
验证码
手机/邮箱/用户名
密码
立即登录即可访问所有OFweek服务
还不是会员?免费注册
忘记密码其他方式
请输入评论内容...
请输入评论/评论长度6~500个字
暂无评论
暂无评论