









一文详解Flink知识体系
失败率重启策略可以在flink-conf.yaml中设置下面的配置参数来启用:
restart-strategy:failure-rate
配置参数描述默认值restart-strategy.failure-rate.max-failures-per-interval在一个Job认定为失败之前,最大的重启次数1restart-strategy.failure-rate.failure-rate-interval计算失败率的时间间隔1分钟restart-strategy.failure-rate.delay两次连续重启尝试之间的时间间隔akka.ask.timeout
例子:
restart-strategy.failure-rate.max-failures-per-interval: 3
restart-strategy.failure-rate.failure-rate-interval: 5 min
restart-strategy.failure-rate.delay: 10 s
失败率重启策略也可以在程序中设置:
val env = ExecutionEnvironment.getExecutionEnvironment()
env.setRestartStrategy(RestartStrategies.failureRateRestart(
3, // 每个测量时间间隔最大失败次数
Time.of(5, TimeUnit.MINUTES), //失败率测量的时间间隔
Time.of(10, TimeUnit.SECONDS) // 两次连续重启尝试的时间间隔
))
4) 无重启策略
Job直接失败,不会尝试进行重启
restart-strategy: none
无重启策略也可以在程序中设置
val env = ExecutionEnvironment.getExecutionEnvironment()
env.setRestartStrategy(RestartStrategies.noRestart())
5) 案例
需求:输入五次zhangsan,程序挂掉。
代码:
import org.apache.flink.api.common.restartstrategy.RestartStrategies
import org.apache.flink.runtime.state.filesystem.FsStateBackend
import org.apache.flink.streaming.api.environment.CheckpointConfig.ExternalizedCheckpointCleanup
import org.apache.flink.streaming.api.scala._
object FixDelayRestartStrategiesDemo {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
//如果想要开启重启策略,就必须开启CheckPoint
env.enableCheckpointing(5000L)
//指定状态存储后端,默认就是内存
//现在指定的是FsStateBackend,支持本地系统、
//new FsStateBackend要指定存储系统的协议:scheme (hdfs://, file://, etc)
env.setStateBackend(new FsStateBackend(args(0)))
//如果程序被cancle,保留以前做的checkpoint
env.getCheckpointConfig.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
//指定以后存储多个checkpoint目录
env.getCheckpointConfig.setMaxConcurrentCheckpoints(2)
//指定重启策略,默认的重启策略是不停的重启
//程序出现异常是会重启,重启五次,每次延迟5秒,如果超过了5次,程序退出
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(5, 5000))
val lines: DataStream[String] = env.socketTextStream(args(1), 8888)
val result = lines.flatMap(_.split(" ").map(word => {
if(word.equals("zhangsan")) {
throw new RuntimeException("zhangsan,程序重启!");
}
(word, 1)
})).keyBy(0).sum(1)
result.print()
env.execute()
}
}
3) checkpoint 案例
1. 需求:
假定用户需要每隔1秒钟需要统计4秒中窗口中数据的量,然后对统计的结果值进行checkpoint处理
2. 数据规划:
使用自定义算子每秒钟产生大约10000条数据。产生的数据为一个四元组(Long,String,String,Integer)—------(id,name,info,count)。数据经统计后,统计结果打印到终端输出。打印输出的结果为Long类型的数据 。
3. 开发思路:
source算子每隔1秒钟发送10000条数据,并注入到Window算子中。window算子每隔1秒钟统计一次最近4秒钟内数据数量。每隔1秒钟将统计结果打印到终端。每隔6秒钟触发一次checkpoint,然后将checkpoint的结果保存到HDFS中。
5. 开发步骤:
获取流处理执行环境
设置检查点机制
自定义数据源
数据分组
划分时间窗口
数据聚合
数据打印
触发执行
示例代码:
//发送数据形式
case class SEvent(id: Long, name: String, info: String, count: Int)
class SEventSourceWithChk extends RichSourceFunction[SEvent]{
private var count = 0L
private var isRunning = true
private val alphabet = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWZYX0987654321"
// 任务取消时调用
override def cancel(): Unit = {
isRunning = false
}
//// source算子的逻辑,即:每秒钟向流图中注入10000个元组
override def run(sourceContext: SourceContext[SEvent]): Unit = {
while(isRunning) {
for (i <- 0 until 10000) {
sourceContext.collect(SEvent(1, "hello-"+count, alphabet,1))
count += 1L
}
Thread.sleep(1000)
}
}
}
*
该段代码是流图定义代码,具体实现业务流程,另外,代码中窗口的触发时间使 用了event time。
object FlinkEventTimeAPIChkMain {
def main(args: Array[String]): Unit ={
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStateBackend(new FsStateBackend("hdfs://hadoop01:9000/flink-checkpoint/checkpoint/"))
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
env.getCheckpointConfig.setCheckpointInterval(6000)
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
//保留策略:默认情况下,检查点不会被保留,仅用于故障中恢复作业,可以启用外部持久化检查点,同时指定保留策略
//ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION:在作业取消时保留检查点,注意在这种情况下,您必须在取消后手动清理检查点状态
//ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION:当作业被cancel时,删除检查点,检查点状态仅在作业失败时可用
env.getCheckpointConfig.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION)
// 应用逻辑
val source: DataStream[SEvent] = env.addSource(new SEventSourceWithChk)
source.assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks[SEvent] {
// 设置watermark
override def getCurrentWatermark: Watermark = {
new Watermark(System.currentTimeMillis())
}
// 给每个元组打上时间戳
override def extractTimestamp(t: SEvent, l: Long): Long = {
System.currentTimeMillis()
}
})
.keyBy(0)
.window(SlidingEventTimeWindows.of(Time.seconds(4), Time.seconds(1)))
.apply(new WindowStatisticWithChk)
.print()
env.execute()
}
}
//该数据在算子制作快照时用于保存到目前为止算子记录的数据条数。
// 用户自定义状态
class UDFState extends Serializable{
private var count = 0L
// 设置用户自定义状态
def setState(s: Long) = count = s
// 获取用户自定状态
def getState = count
}
//该段代码是window算子的代码,每当触发计算时统计窗口中元组数量。
class WindowStatisticWithChk extends WindowFunction[SEvent, Long, Tuple, TimeWindow] with ListCheckpointed[UDFState]{
private var total = 0L
// window算子的实现逻辑,即:统计window中元组的数量
override def apply(key: Tuple, window: TimeWindow, input: Iterable[SEvent], out: Collector[Long]): Unit = {
var count = 0L
for (event <- input) {
count += 1L
}
total += count
out.collect(count)
}
// 从自定义快照中恢复状态
override def restoreState(state: util.List[UDFState]): Unit = {
val udfState = state.get(0)
total = udfState.getState
}
// 制作自定义状态快照
override def snapshotState(checkpointId: Long, timestamp: Long): util.List[UDFState] = {
val udfList: util.ArrayList[UDFState] = new util.ArrayList[UDFState]
val udfState = new UDFState
udfState.setState(total)
udfList.add(udfState)
udfList
}
}
4. 端对端仅处理一次语义
当谈及仅一次处理时,我们真正想表达的是每条输入消息只会影响最终结果一次!(影响应用状态一次,而非被处理一次)即使出现机器故障或软件崩溃,Flink也要保证不会有数据被重复处理或压根就没有被处理从而影响状态。
在 Flink 1.4 版本之前,精准一次处理只限于 Flink 应用内,也就是所有的 Operator 完全由 Flink 状态保存并管理的才能实现精确一次处理。但 Flink 处理完数据后大多需要将结果发送到外部系统,比如 Sink 到 Kafka 中,这个过程中 Flink 并不保证精准一次处理。
在 Flink 1.4 版本正式引入了一个里程碑式的功能:两阶段提交 Sink,即 TwoPhaseCommitSinkFunction 函数。该 SinkFunction 提取并封装了两阶段提交协议中的公共逻辑,自此 Flink 搭配特定 Source 和 Sink(如 Kafka 0.11 版)实现精确一次处理语义(英文简称:EOS,即 Exactly-Once Semantics)。
在 Flink 中需要端到端精准一次处理的位置有三个:

Flink 端到端精准一次处理
Source 端:数据从上一阶段进入到 Flink 时,需要保证消息精准一次消费。
Flink 内部端:这个我们已经了解,利用 Checkpoint 机制,把状态存盘,发生故障的时候可以恢复,保证内部的状态一致性。不了解的小伙伴可以看下我之前的文章:
Flink可靠性的基石-checkpoint机制详细解析
Sink 端:将处理完的数据发送到下一阶段时,需要保证数据能够准确无误发送到下一阶段。
1) Flink端到端精准一次处理语义(EOS)
以下内容适用于 Flink 1.4 及之后版本
对于 Source 端:Source 端的精准一次处理比较简单,毕竟数据是落到 Flink 中,所以 Flink 只需要保存消费数据的偏移量即可, 如消费 Kafka 中的数据,Flink 将 Kafka Consumer 作为 Source,可以将偏移量保存下来,如果后续任务出现了故障,恢复的时候可以由连接器重置偏移量,重新消费数据,保证一致性。
对于 Sink 端:Sink 端是最复杂的,因为数据是落地到其他系统上的,数据一旦离开 Flink 之后,Flink 就监控不到这些数据了,所以精准一次处理语义必须也要应用于 Flink 写入数据的外部系统,故这些外部系统必须提供一种手段允许提交或回滚这些写入操作,同时还要保证与 Flink Checkpoint 能够协调使用(Kafka 0.11 版本已经实现精确一次处理语义)。
我们以 Flink 与 Kafka 组合为例,Flink 从 Kafka 中读数据,处理完的数据在写入 Kafka 中。
为什么以Kafka为例,第一个原因是目前大多数的 Flink 系统读写数据都是与 Kafka 系统进行的。第二个原因,也是最重要的原因 Kafka 0.11 版本正式发布了对于事务的支持,这是与Kafka交互的Flink应用要实现端到端精准一次语义的必要条件。
当然,Flink 支持这种精准一次处理语义并不只是限于与 Kafka 的结合,可以使用任何 Source/Sink,只要它们提供了必要的协调机制。
2) Flink 与 Kafka 组合

Flink 应用示例
如上图所示,Flink 中包含以下组件:
一个 Source,从 Kafka 中读取数据(即 KafkaConsumer)
一个时间窗口化的聚会操作(Window)
一个 Sink,将结果写入到 Kafka(即 KafkaProducer)
若要 Sink 支持精准一次处理语义(EOS),它必须以事务的方式写数据到 Kafka,这样当提交事务时两次 Checkpoint 间的所有写入操作当作为一个事务被提交。这确保了出现故障或崩溃时这些写入操作能够被回滚。
当然了,在一个分布式且含有多个并发执行 Sink 的应用中,仅仅执行单次提交或回滚是不够的,因为所有组件都必须对这些提交或回滚达成共识,这样才能保证得到一个一致性的结果。Flink 使用两阶段提交协议以及预提交(Pre-commit)阶段来解决这个问题。
3) 两阶段提交协议(2PC)
两阶段提交协议(Two-Phase Commit,2PC)是很常用的解决分布式事务问题的方式,它可以保证在分布式事务中,要么所有参与进程都提交事务,要么都取消,即实现 ACID 中的 A (原子性)。
在数据一致性的环境下,其代表的含义是:要么所有备份数据同时更改某个数值,要么都不改,以此来达到数据的强一致性。
两阶段提交协议中有两个重要角色,协调者(Coordinator)和参与者(Participant),其中协调者只有一个,起到分布式事务的协调管理作用,参与者有多个。
顾名思义,两阶段提交将提交过程划分为连续的两个阶段:表决阶段(Voting)和提交阶段(Commit)。
两阶段提交协议过程如下图所示:

两阶段提交协议
第一阶段:表决阶段
协调者向所有参与者发送一个 VOTE_REQUEST 消息。
当参与者接收到 VOTE_REQUEST 消息,向协调者发送 VOTE_COMMIT 消息作为回应,告诉协调者自己已经做好准备提交准备,如果参与者没有准备好或遇到其他故障,就返回一个 VOTE_ABORT 消息,告诉协调者目前无法提交事务。
第二阶段:提交阶段
协调者收集来自各个参与者的表决消息。如果所有参与者一致认为可以提交事务,那么协调者决定事务的最终提交,在此情形下协调者向所有参与者发送一个 GLOBAL_COMMIT 消息,通知参与者进行本地提交;如果所有参与者中有任意一个返回消息是 VOTE_ABORT,协调者就会取消事务,向所有参与者广播一条 GLOBAL_ABORT 消息通知所有的参与者取消事务。
每个提交了表决信息的参与者等候协调者返回消息,如果参与者接收到一个 GLOBAL_COMMIT 消息,那么参与者提交本地事务,否则如果接收到 GLOBAL_ABORT 消息,则参与者取消本地事务。
4) 两阶段提交协议在 Flink 中的应用
Flink 的两阶段提交思路:
我们从 Flink 程序启动到消费 Kafka 数据,最后到 Flink 将数据 Sink 到 Kafka 为止,来分析 Flink 的精准一次处理。
当 Checkpoint 启动时,JobManager 会将检查点分界线(checkpoint battier)注入数据流,checkpoint barrier 会在算子间传递下去,如下如所示:

Flink 精准一次处理:Checkpoint 启动
Source 端:Flink Kafka Source 负责保存 Kafka 消费 offset,当 Chckpoint 成功时 Flink 负责提交这些写入,否则就终止取消掉它们,当 Chckpoint 完成位移保存,它会将 checkpoint barrier(检查点分界线) 传给下一个 Operator,然后每个算子会对当前的状态做个快照,保存到状态后端(State Backend)。
对于 Source 任务而言,就会把当前的 offset 作为状态保存起来。下次从 Checkpoint 恢复时,Source 任务可以重新提交偏移量,从上次保存的位置开始重新消费数据,如下图所示:

Flink 精准一次处理:checkpoint barrier 及 offset 保存Slink 端:从 Source 端开始,每个内部的 transform 任务遇到 checkpoint barrier(检查点分界线)时,都会把状态存到 Checkpoint 里。数据处理完毕到 Sink 端时,Sink 任务首先把数据写入外部 Kafka,这些数据都属于预提交的事务(还不能被消费),此时的 Pre-commit 预提交阶段下 Data Sink 在保存状态到状态后端的同时还必须预提交它的外部事务,如下图所示:

Flink 精准一次处理:预提交到外部系统
当所有算子任务的快照完成(所有创建的快照都被视为是 Checkpoint 的一部分),也就是这次的 Checkpoint 完成时,JobManager 会向所有任务发通知,确认这次 Checkpoint 完成,此时 Pre-commit 预提交阶段才算完成。才正式到两阶段提交协议的第二个阶段:commit 阶段。该阶段中 JobManager 会为应用中每个 Operator 发起 Checkpoint 已完成的回调逻辑。
本例中的 Data Source 和窗口操作无外部状态,因此在该阶段,这两个 Opeartor 无需执行任何逻辑,但是 Data Sink 是有外部状态的,此时我们必须提交外部事务,当 Sink 任务收到确认通知,就会正式提交之前的事务,Kafka 中未确认的数据就改为“已确认”,数据就真正可以被消费了,如下图所示:

Flink 精准一次处理:数据精准被消费
注:Flink 由 JobManager 协调各个 TaskManager 进行 Checkpoint 存储,Checkpoint 保存在 StateBackend(状态后端) 中,默认 StateBackend 是内存级的,也可以改为文件级的进行持久化保存。
最后,一张图总结下 Flink 的 EOS:

Flink 端到端精准一次处理
此图建议保存,总结全面且简明扼要,再也不怂面试官!
5) Exactly-Once 案例
Kafka来实现End-to-End Exactly-Once语义:
import java.util.Properties
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.streaming.api.CheckpointingMode
import org.apache.flink.streaming.api.environment.CheckpointConfig
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer011
import org.apache.flink.streaming.util.serialization.KeyedSerializationSchemaWrapper
*
* Kafka Producer的容错-Kafka 0.9 and 0.10
* 如果Flink开启了checkpoint,针对FlinkKafkaProducer09 和FlinkKafkaProducer010 可以提供 at-least-once的语义,还需要配置下面两个参数
* ?setLogFailuresOnly(false)
* ?setFlushOnCheckpoint(true)
*
* 注意:建议修改kafka 生产者的重试次数
* retries【这个参数的值默认是0】
*
* Kafka Producer的容错-Kafka 0.11
* 如果Flink开启了checkpoint,针对FlinkKafkaProducer011 就可以提供 exactly-once的语义
* 但是需要选择具体的语义
* ?Semantic.NONE
* ?Semantic.AT_LEAST_ONCE【默认】
* ?Semantic.EXACTLY_ONCE
object StreamingKafkaSinkScala {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
//隐式转换
import org.apache.flink.api.scala._
//checkpoint配置
env.enableCheckpointing(5000)
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
env.getCheckpointConfig.setMinPauseBetweenCheckpoints(500)
env.getCheckpointConfig.setCheckpointTimeout(60000)
env.getCheckpointConfig.setMaxConcurrentCheckpoints(1)
env.getCheckpointConfig.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
val text = env.socketTextStream("node01", 9001, '')
val topic = "test"
val prop = new Properties()
prop.setProperty("bootstrap.servers", "node01:9092")
//设置事务超时时间,也可在kafka配置中设置
prop.setProperty("transaction.timeout.ms",60000*15+"");
//使用至少一次语义的形式
//val myProducer = new FlinkKafkaProducer011(brokerList, topic, new SimpleStringSchema());
//使用支持仅一次语义的形式
val myProducer =
new FlinkKafkaProducer011[String](topic, new KeyedSerializationSchemaWrapper[String](new SimpleStringSchema), prop, FlinkKafkaProducer011.Semantic.EXACTLY_ONCE);
text.addSink(myProducer)
env.execute("StreamingKafkaSinkScala")
}
}
Redis实现End-to-End Exactly-Once语义:
代码开发步骤:
获取流处理执行环境设置检查点机制定义kafkaConsumer数据转换:分组,求和数据写入redis触发执行object ExactlyRedisSink {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
env.enableCheckpointing(5000)
env.setStateBackend(new FsStateBackend("hdfs://node01:8020/check/11"))
env.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE)
env.getCheckpointConfig.setCheckpointTimeout(60000)
env.getCheckpointConfig.setFailOnCheckpointingErrors(false)
env.getCheckpointConfig.setMaxConcurrentCheckpoints(1)
env.getCheckpointConfig.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION)
//设置kafka,加载kafka数据源
val properties = new Properties()
properties.setProperty("bootstrap.servers", "node01:9092,node02:9092,node03:9092")
properties.setProperty("group.id", "test")
properties.setProperty("enable.auto.commit", "false")
val kafkaConsumer = new FlinkKafkaConsumer011[String]("test2", new SimpleStringSchema(), properties)
kafkaConsumer.setStartFromLatest()
//检查点制作成功,才开始提交偏移量
kafkaConsumer.setCommitOffsetsOnCheckpoints(true)
val kafkaSource: DataStream[String] = env.addSource(kafkaConsumer)
//数据转换
val sumData: DataStream[(String, Int)] = kafkaSource.flatMap(_.split(" "))
.map(_ -> 1)
.keyBy(0)
.sum(1)
val set = new util.HashSet[InetSocketAddress]()
set.add(new InetSocketAddress(InetAddress.getByName("node01"),7001))
set.add(new InetSocketAddress(InetAddress.getByName("node01"),7002))
set.add(new InetSocketAddress(InetAddress.getByName("node01"),7003))
val config: FlinkJedisClusterConfig = new FlinkJedisClusterConfig.Builder()
.setNodes(set)
.setMaxIdle(5)
.setMaxTotal(10)
.setMinIdle(5)
.setTimeout(10)
.build()
//数据写入
sumData.addSink(new RedisSink(config,new MyRedisSink))
env.execute()
}
}
class MyRedisSink extends RedisMapper[(String,Int)] {
override def getCommandDescription: RedisCommandDescription = {
new RedisCommandDescription(RedisCommand.HSET,"resink")
}
override def getKeyFromData(data: (String, Int)): String = {
data._1
}
override def getValueFromData(data: (String, Int)): String = {
data._2.toString
}
}
八、Flink SQL
Flink SQL 是 Flink 实时计算为简化计算模型,降低用户使用实时计算门槛而设计的一套符合标准 SQL 语义的开发语言。自 2015 年开始,阿里巴巴开始调研开源流计算引擎,最终决定基于 Flink 打造新一代计算引擎,针对 Flink 存在的不足进行优化和改进,并且在 2019 年初将最终代码开源,也就是我们熟知的 Blink。Blink 在原来的 Flink 基础上最显著的一个贡献就是 Flink SQL 的实现。
Flink SQL 是面向用户的 API 层,在我们传统的流式计算领域,比如 Storm、Spark Streaming 都会提供一些 Function 或者 Datastream API,用户通过 Java 或 Scala 写业务逻辑,这种方式虽然灵活,但有一些不足,比如具备一定门槛且调优较难,随着版本的不断更新,API 也出现了很多不兼容的地方。
在这个背景下,毫无疑问,SQL 就成了我们最佳选择,之所以选择将 SQL 作为核心 API,是因为其具有几个非常重要的特点:
SQL 属于设定式语言,用户只要表达清楚需求即可,不需要了解具体做法;
SQL 可优化,内置多种查询优化器,这些查询优化器可为 SQL 翻译出最优执行计划;
SQL 易于理解,不同行业和领域的人都懂,学习成本较低;
SQL 非常稳定,在数据库 30 多年的历史中,SQL 本身变化较少;
流与批的统一,Flink 底层 Runtime 本身就是一个流与批统一的引擎,而 SQL 可以做到 API 层的流与批统一。
1. Flink SQL 常用算子
SELECT:
SELECT 用于从 DataSet/DataStream 中选择数据,用于筛选出某些列。
示例:
SELECT * FROM Table; // 取出表中的所有列
SELECT name,age FROM Table; // 取出表中 name 和 age 两列
与此同时 SELECT 语句中可以使用函数和别名,例如我们上面提到的 WordCount 中:
SELECT word, COUNT(word) FROM table GROUP BY word;
WHERE:
WHERE 用于从数据集/流中过滤数据,与 SELECT 一起使用,用于根据某些条件对关系做水平分割,即选择符合条件的记录。
示例:
SELECT name,age FROM Table where name LIKE ‘% 小明 %’;
SELECT * FROM Table WHERE age = 20;
WHERE 是从原数据中进行过滤,那么在 WHERE 条件中,Flink SQL 同样支持 =、<、>、、>=、<=,以及 AND、OR 等表达式的组合,最终满足过滤条件的数据会被选择出来。并且 WHERE 可以结合 IN、NOT IN 联合使用。举个例子:
SELECT name, age
FROM Table
WHERE name IN (SELECT name FROM Table2)
DISTINCT:
DISTINCT 用于从数据集/流中去重根据 SELECT 的结果进行去重。
示例:
SELECT DISTINCT name FROM Table;
对于流式查询,计算查询结果所需的 State 可能会无限增长,用户需要自己控制查询的状态范围,以防止状态过大。
GROUP BY:
GROUP BY 是对数据进行分组操作。例如我们需要计算成绩明细表中,每个学生的总分。
示例:
SELECT name, SUM(score) as TotalScore FROM Table GROUP BY name;
UNION 和 UNION ALL:
UNION 用于将两个结果集合并起来,要求两个结果集字段完全一致,包括字段类型、字段顺序。不同于 UNION ALL 的是,UNION 会对结果数据去重。
示例:
SELECT * FROM T1 UNION (ALL) SELECT * FROM T2;
JOIN:
JOIN 用于把来自两个表的数据联合起来形成结果表,Flink 支持的 JOIN 类型包括:
JOIN - INNER JOIN
LEFT JOIN - LEFT OUTER JOIN
RIGHT JOIN - RIGHT OUTER JOIN
FULL JOIN - FULL OUTER JOIN
这里的 JOIN 的语义和我们在关系型数据库中使用的 JOIN 语义一致。
示例:
JOIN(将订单表数据和商品表进行关联)
SELECT * FROM Orders INNER JOIN Product ON Orders.productId = Product.id
LEFT JOIN 与 JOIN 的区别是当右表没有与左边相 JOIN 的数据时候,右边对应的字段补 NULL 输出,RIGHT JOIN 相当于 LEFT JOIN 左右两个表交互一下位置。FULL JOIN 相当于 RIGHT JOIN 和 LEFT JOIN 之后进行 UNION ALL 操作。
示例:
SELECT * FROM Orders LEFT JOIN Product ON Orders.productId = Product.id
SELECT * FROM Orders RIGHT JOIN Product ON Orders.productId = Product.id
SELECT * FROM Orders FULL OUTER JOIN Product ON Orders.productId = Product.id
Group Window:
根据窗口数据划分的不同,目前 Apache Flink 有如下 3 种 Bounded Window:
Tumble,滚动窗口,窗口数据有固定的大小,窗口数据无叠加;
Hop,滑动窗口,窗口数据有固定大小,并且有固定的窗口重建频率,窗口数据有叠加;
Session,会话窗口,窗口数据没有固定的大小,根据窗口数据活跃程度划分窗口,窗口数据无叠加。
Tumble Window:
Tumble 滚动窗口有固定大小,窗口数据不重叠,具体语义如下:

Tumble 滚动窗口对应的语法如下:
SELECT
[gk],
[TUMBLE_START(timeCol, size)],
[TUMBLE_END(timeCol, size)],
agg1(col1),
...
aggn(colN)
FROM Tab1
GROUP BY [gk], TUMBLE(timeCol, size)
其中:
[gk] 决定了是否需要按照字段进行聚合;
TUMBLE_START 代表窗口开始时间;
TUMBLE_END 代表窗口结束时间;
timeCol 是流表中表示时间字段;
size 表示窗口的大小,如 秒、分钟、小时、天。
举个例子,假如我们要计算每个人每天的订单量,按照 user 进行聚合分组:
SELECT user,
TUMBLE_START(rowtime, INTERVAL ‘1’ DAY) as wStart,
SUM(amount)
FROM Orders
GROUP BY TUMBLE(rowtime, INTERVAL ‘1’ DAY), user;
Hop Window:
Hop 滑动窗口和滚动窗口类似,窗口有固定的 size,与滚动窗口不同的是滑动窗口可以通过 slide 参数控制滑动窗口的新建频率。因此当 slide 值小于窗口 size 的值的时候多个滑动窗口会重叠,具体语义如下:

Hop 滑动窗口对应语法如下:
SELECT
[gk],
[HOP_START(timeCol, slide, size)] ,
[HOP_END(timeCol, slide, size)],
agg1(col1),
...
aggN(colN)
FROM Tab1
GROUP BY [gk], HOP(timeCol, slide, size)
每次字段的意思和 Tumble 窗口类似:
[gk] 决定了是否需要按照字段进行聚合;
HOP_START 表示窗口开始时间;
HOP_END 表示窗口结束时间;
timeCol 表示流表中表示时间字段;
slide 表示每次窗口滑动的大小;
size 表示整个窗口的大小,如 秒、分钟、小时、天。
举例说明,我们要每过一小时计算一次过去 24 小时内每个商品的销量:
SELECT product,
SUM(amount)
FROM Orders
GROUP BY HOP(rowtime, INTERVAL '1' HOUR, INTERVAL '1' DAY), product
Session Window:
会话时间窗口没有固定的持续时间,但它们的界限由 interval 不活动时间定义,即如果在定义的间隙期间没有出现事件,则会话窗口关闭。

Seeeion 会话窗口对应语法如下:
SELECT
[gk],
SESSION_START(timeCol, gap) AS winStart,
SESSION_END(timeCol, gap) AS winEnd,
agg1(col1),
...
aggn(colN)
FROM Tab1
GROUP BY [gk], SESSION(timeCol, gap)
[gk] 决定了是否需要按照字段进行聚合;
SESSION_START 表示窗口开始时间;
SESSION_END 表示窗口结束时间;
timeCol 表示流表中表示时间字段;
gap 表示窗口数据非活跃周期的时长。
例如,我们需要计算每个用户访问时间 12 小时内的订单量:
SELECT user,
SESSION_START(rowtime, INTERVAL ‘12’ HOUR) AS sStart,
SESSION_ROWTIME(rowtime, INTERVAL ‘12’ HOUR) AS sEnd,
SUM(amount)
FROM Orders
GROUP BY SESSION(rowtime, INTERVAL ‘12’ HOUR), user
Table API和SQL捆绑在flink-table Maven工件中。必须将以下依赖项添加到你的项目才能使用Table API和SQL:
另外,你需要为Flink的Scala批处理或流式API添加依赖项。对于批量查询,您需要添加:
2. Flink SQL 实战案例1) 批数据SQL
用法:
构建Table运行环境将DataSet注册为一张表使用Table运行环境的 sqlQuery 方法来执行SQL语句
示例:使用Flink SQL统计用户消费订单的总金额、最大金额、最小金额、订单总数。
订单id用户名订单日期消费金额1Zhangsan2018-10-20 15:30358.5
测试数据(订单ID、用户名、订单日期、订单金额):
Order(1, "zhangsan", "2018-10-20 15:30", 358.5),
Order(2, "zhangsan", "2018-10-20 16:30", 131.5),
Order(3, "lisi", "2018-10-20 16:30", 127.5),
Order(4, "lisi", "2018-10-20 16:30", 328.5),
Order(5, "lisi", "2018-10-20 16:30", 432.5),
Order(6, "zhaoliu", "2018-10-20 22:30", 451.0),
Order(7, "zhaoliu", "2018-10-20 22:30", 362.0),
Order(8, "zhaoliu", "2018-10-20 22:30", 364.0),
Order(9, "zhaoliu", "2018-10-20 22:30", 341.0)
步骤:
获取一个批处理运行环境获取一个Table运行环境创建一个样例类 Order 用来映射数据(订单名、用户名、订单日期、订单金额)基于本地 Order 集合创建一个DataSet source使用Table运行环境将DataSet注册为一张表使用SQL语句来操作数据(统计用户消费订单的总金额、最大金额、最小金额、订单总数)使用TableEnv.toDataSet将Table转换为DataSet打印测试
示例代码:
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.table.api.{Table, TableEnvironment}
import org.apache.flink.table.api.scala.BatchTableEnvironment
import org.apache.flink.api.scala._
import org.apache.flink.types.Row
*
* 使用Flink SQL统计用户消费订单的总金额、最大金额、最小金额、订单总数。
object BatchFlinkSqlDemo {
//3. 创建一个样例类 Order 用来映射数据(订单名、用户名、订单日期、订单金额)
case class Order(id:Int, userName:String, createTime:String, money:Double)
def main(args: Array[String]): Unit = {
*
* 实现思路:
* 1. 获取一个批处理运行环境
* 2. 获取一个Table运行环境
* 3. 创建一个样例类 Order 用来映射数据(订单名、用户名、订单日期、订单金额)
* 4. 基于本地 Order 集合创建一个DataSet source
* 5. 使用Table运行环境将DataSet注册为一张表
* 6. 使用SQL语句来操作数据(统计用户消费订单的总金额、最大金额、最小金额、订单总数)
* 7. 使用TableEnv.toDataSet将Table转换为DataSet
* 8. 打印测试
//1. 获取一个批处理运行环境
val env: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
//2. 获取一个Table运行环境
val tabEnv: BatchTableEnvironment = TableEnvironment.getTableEnvironment(env)
//4. 基于本地 Order 集合创建一个DataSet source
val orderDataSet: DataSet[Order] = env.fromElements(
Order(1, "zhangsan", "2018-10-20 15:30", 358.5),
Order(2, "zhangsan", "2018-10-20 16:30", 131.5),
Order(3, "lisi", "2018-10-20 16:30", 127.5),
Order(4, "lisi", "2018-10-20 16:30", 328.5),
Order(5, "lisi", "2018-10-20 16:30", 432.5),
Order(6, "zhaoliu", "2018-10-20 22:30", 451.0),
Order(7, "zhaoliu", "2018-10-20 22:30", 362.0),
Order(8, "zhaoliu", "2018-10-20 22:30", 364.0),
Order(9, "zhaoliu", "2018-10-20 22:30", 341.0)
)
//5. 使用Table运行环境将DataSet注册为一张表
tabEnv.registerDataSet("t_order", orderDataSet)
//6. 使用SQL语句来操作数据(统计用户消费订单的总金额、最大金额、最小金额、订单总数)
//用户消费订单的总金额、最大金额、最小金额、订单总数。
val sql =
"""
| select
| userName,
| sum(money) totalMoney,
| max(money) maxMoney,
| min(money) minMoney,
| count(1) totalCount
| from t_order
| group by userName
|""".stripMargin //在scala中stripMargin默认是“|”作为多行连接符
//7. 使用TableEnv.toDataSet将Table转换为DataSet
val table: Table = tabEnv.sqlQuery(sql)
table.printSchema()
tabEnv.toDataSet[Row](table).print()
}
}
2) 流数据SQL
流处理中也可以支持SQL。但是需要注意以下几点:
要使用流处理的SQL,必须要添加水印时间使用 registerDataStream 注册表的时候,使用 ' 来指定字段注册表的时候,必须要指定一个rowtime,否则无法在SQL中使用窗口必须要导入 import org.apache.flink.table.api.scala._ 隐式参数SQL中使用 trumble(时间列名, interval '时间' sencond) 来进行定义窗口
示例:使用Flink SQL来统计5秒内 用户的 订单总数、订单的最大金额、订单的最小金额。
步骤
获取流处理运行环境获取Table运行环境设置处理时间为 EventTime创建一个订单样例类 Order ,包含四个字段(订单ID、用户ID、订单金额、时间戳)创建一个自定义数据源使用for循环生成1000个订单随机生成订单ID(UUID)随机生成用户ID(0-2)随机生成订单金额(0-100)时间戳为当前系统时间每隔1秒生成一个订单添加水印,允许延迟2秒导入 import org.apache.flink.table.api.scala._ 隐式参数使用 registerDataStream 注册表,并分别指定字段,还要指定rowtime字段编写SQL语句统计用户订单总数、最大金额、最小金额分组时要使用 tumble(时间列, interval '窗口时间' second) 来创建窗口使用 tableEnv.sqlQuery 执行sql语句将SQL的执行结果转换成DataStream再打印出来启动流处理程序
示例代码:
import java.util.UUID
import java.util.concurrent.TimeUnit
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.functions.source.{RichSourceFunction, SourceFunction}
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.table.api.{Table, TableEnvironment}
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarks
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
import org.apache.flink.streaming.api.watermark.Watermark
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.types.Row
import scala.util.Random
*
* 需求:
* 使用Flink SQL来统计5秒内 用户的 订单总数、订单的最大金额、订单的最小金额
*
* timestamp是关键字不能作为字段的名字(关键字不能作为字段名字)
object StreamFlinkSqlDemo {
*
* 1. 获取流处理运行环境
* 2. 获取Table运行环境
* 3. 设置处理时间为 EventTime
* 4. 创建一个订单样例类 Order ,包含四个字段(订单ID、用户ID、订单金额、时间戳)
* 5. 创建一个自定义数据源
* 使用for循环生成1000个订单
* 随机生成订单ID(UUID)
* 随机生成用户ID(0-2)
* 随机生成订单金额(0-100)
* 时间戳为当前系统时间
* 每隔1秒生成一个订单
* 6. 添加水印,允许延迟2秒
* 7. 导入 import org.apache.flink.table.api.scala._ 隐式参数
* 8. 使用 registerDataStream 注册表,并分别指定字段,还要指定rowtime字段
* 9. 编写SQL语句统计用户订单总数、最大金额、最小金额
* 分组时要使用 tumble(时间列, interval '窗口时间' second) 来创建窗口
* 10. 使用 tableEnv.sqlQuery 执行sql语句
* 11. 将SQL的执行结果转换成DataStream再打印出来
* 12. 启动流处理程序
// 3. 创建一个订单样例类`Order`,包含四个字段(订单ID、用户ID、订单金额、时间戳)
case class Order(orderId:String, userId:Int, money:Long, createTime:Long)
def main(args: Array[String]): Unit = {
// 1. 创建流处理运行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// 2. 设置处理时间为`EventTime`
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
//获取table的运行环境
val tableEnv = TableEnvironment.getTableEnvironment(env)
// 4. 创建一个自定义数据源
val orderDataStream = env.addSource(new RichSourceFunction[Order] {
var isRunning = true
override def run(ctx: SourceFunction.SourceContext[Order]): Unit = {
// - 随机生成订单ID(UUID)
// - 随机生成用户ID(0-2)
// - 随机生成订单金额(0-100)
// - 时间戳为当前系统时间
// - 每隔1秒生成一个订单
for (i <- 0 until 1000 if isRunning) {
val order = Order(UUID.randomUUID().toString, Random.nextInt(3), Random.nextInt(101),
System.currentTimeMillis())
TimeUnit.SECONDS.sleep(1)
ctx.collect(order)
}
}
override def cancel(): Unit = { isRunning = false }
})
// 5. 添加水印,允许延迟2秒
val watermarkDataStream = orderDataStream.assignTimestampsAndWatermarks(
new BoundedOutOfOrdernessTimestampExtractor[Order](Time.seconds(2)) {
override def extractTimestamp(element: Order): Long = {
val eventTime = element.createTime
eventTime
}
}
)
// 6. 导入`import org.apache.flink.table.api.scala._`隐式参数
// 7. 使用`registerDataStream`注册表,并分别指定字段,还要指定rowtime字段
import org.apache.flink.table.api.scala._
tableEnv.registerDataStream("t_order", watermarkDataStream, 'orderId, 'userId, 'money,'createTime.rowtime)
// 8. 编写SQL语句统计用户订单总数、最大金额、最小金额
// - 分组时要使用`tumble(时间列, interval '窗口时间' second)`来创建窗口
val sql =
"""
|select
| userId,
| count(1) as totalCount,
| max(money) as maxMoney,
| min(money) as minMoney
| from
| t_order
| group by
| tumble(createTime, interval '5' second),
| userId
""".stripMargin
// 9. 使用`tableEnv.sqlQuery`执行sql语句
val table: Table = tableEnv.sqlQuery(sql)
// 10. 将SQL的执行结果转换成DataStream再打印出来
table.toRetractStream[Row].print()
env.execute("StreamSQLApp")
}
}
九、Flink CEP
我们在看直播的时候,不管对于主播还是用户来说,非常重要的一项就是弹幕文化。为了增加直播趣味性和互动性, 各大网络直播平台纷纷采用弹窗弹幕作为用户实时交流的方式,内容丰富且形式多样的弹幕数据中隐含着复杂的用户属性与用户行为, 研究并理解在线直播平台用户具有弹幕内容审核与监控、舆论热点预测、个性化摘要标注等多方面的应用价值。
本文不分析弹幕数据的应用价值,只通过弹幕内容审核与监控案例来了解下Flink CEP的概念及功能。
在用户发弹幕时,直播平台主要实时监控识别两类弹幕内容:一类是发布不友善弹幕的用户 ,一类是刷屏的用户。
我们先记住上述需要实时监控识别的两类用户,接下来介绍Flink CEP的API,然后使用CEP解决上述问题。
本文首发于公众号【五分钟学大数据】,大数据领域原创技术号
1. Flink CEP 是什么
Flink CEP是一个基于Flink的复杂事件处理库,可以从多个数据流中发现复杂事件,识别有意义的事件(例如机会或者威胁),并尽快的做出响应,而不是需要等待几天或则几个月相当长的时间,才发现问题。
2. Flink CEP API
CEP API的核心是Pattern(模式) API,它允许你快速定义复杂的事件模式。每个模式包含多个阶段(stage)或者我们也可称为状态(state)。从一个状态切换到另一个状态,用户可以指定条件,这些条件可以作用在邻近的事件或独立事件上。
介绍API之前先来理解几个概念:
1) 模式与模式序列
简单模式称为模式,将最终在数据流中进行搜索匹配的复杂模式序列称为模式序列,每个复杂模式序列是由多个简单模式组成。
每个模式必须具有唯一的名称,我们可以使用模式名称来标识该模式匹配到的事件。
2) 单个模式
一个模式既可以是单例的,也可以是循环的。单例模式接受单个事件,循环模式可以接受多个事件。
3) 模式示例:
有如下模式:a b+ c?d
其中a,b,c,d这些字母代表的是模式,+代表循环,b+就是循环模式;?代表可选,c?就是可选模式;
所以上述模式的意思就是:a后面可以跟一个或多个b,后面再可选的跟c,最后跟d。
其中a、c? 、d是单例模式,b+是循环模式。
一般情况下,模式都是单例模式,可以使用量词(Quantifiers)将其转换为循环模式。
每个模式可以带有一个或多个条件,这些条件是基于事件接收进行定义的。或者说,每个模式通过一个或多个条件来匹配和接收事件。
了解完上述概念后,接下来介绍下案例中需要用到的几个CEP API:
4) 案例中用到的CEP API:
Begin:定义一个起始模式状态
用法:start = Pattern.
Next:附加一个新的模式状态。匹配事件必须直接接续上一个匹配事件
用法:next = start.next("next");
Where:定义当前模式状态的过滤条件。仅当事件通过过滤器时,它才能与状态匹配
用法:patternState.where(_.message == "yyds");
Within: 定义事件序列与模式匹配的最大时间间隔。如果未完成的事件序列超过此时间,则将其丢弃
用法:patternState.within(Time.seconds(10));
Times:一个给定类型的事件出现了指定次数
用法:patternState.times(5);
API 先介绍以上这几个,接下来我们解决下文章开头提到的案例:
3. 监测用户弹幕行为案例案例一:监测恶意用户
规则:用户如果在10s内,同时输入 TMD 超过5次,就认为用户为恶意攻击,识别出该用户。
使用 Flink CEP 检测恶意用户:
import org.apache.flink.api.scala._
import org.apache.flink.cep.PatternSelectFunction
import org.apache.flink.cep.scala.{CEP, PatternStream}
import org.apache.flink.cep.scala.pattern.Pattern
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.scala.{DataStream, OutputTag, StreamExecutionEnvironment}
import org.apache.flink.streaming.api.windowing.time.Time
object BarrageBehavior01 {
case class LoginEvent(userId:String, message:String, timestamp:Long){
override def toString: String = userId
}
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 使用IngestionTime作为EventTime
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
// 用于观察测试数据处理顺序
env.setParallelism(1)
// 模拟数据源
val loginEventStream: DataStream[LoginEvent] = env.fromCollection(
List(
LoginEvent("1", "TMD", 1618498576),
LoginEvent("1", "TMD", 1618498577),
LoginEvent("1", "TMD", 1618498579),
LoginEvent("1", "TMD", 1618498582),
LoginEvent("2", "TMD", 1618498583),
LoginEvent("1", "TMD", 1618498585)
)
).assignAscendingTimestamps(_.timestamp * 1000)
//定义模式
val loginEventPattern: Pattern[LoginEvent, LoginEvent] = Pattern.begin[LoginEvent]("begin")
.where(_.message == "TMD")
.times(5)
.within(Time.seconds(10))
//匹配模式
val patternStream: PatternStream[LoginEvent] = CEP.pattern(loginEventStream.keyBy(_.userId), loginEventPattern)
import scala.collection.Map
val result = patternStream.select((pattern:Map[String, Iterable[LoginEvent]])=> {
val first = pattern.getOrElse("begin", null).iterator.next()
(first.userId, first.timestamp)
})
//恶意用户,实际处理可将按用户进行禁言等处理,为简化此处仅打印出该用户
result.print("恶意用户>>>")
env.execute("BarrageBehavior01")
}
}
案例二:监测刷屏用户
规则:用户如果在10s内,同时连续输入同样一句话超过5次,就认为是恶意刷屏。
使用 Flink CEP检测刷屏用户
object BarrageBehavior02 {
case class Message(userId: String, ip: String, msg: String)
def main(args: Array[String]): Unit = {
//初始化运行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//设置并行度
env.setParallelism(1)
// 模拟数据源
val loginEventStream: DataStream[Message] = env.fromCollection(
List(
Message("1", "192.168.0.1", "beijing"),
Message("1", "192.168.0.2", "beijing"),
Message("1", "192.168.0.3", "beijing"),
Message("1", "192.168.0.4", "beijing"),
Message("2", "192.168.10.10", "shanghai"),
Message("3", "192.168.10.10", "beijing"),
Message("3", "192.168.10.11", "beijing"),
Message("4", "192.168.10.10", "beijing"),
Message("5", "192.168.10.11", "shanghai"),
Message("4", "192.168.10.12", "beijing"),
Message("5", "192.168.10.13", "shanghai"),
Message("5", "192.168.10.14", "shanghai"),
Message("5", "192.168.10.15", "beijing"),
Message("6", "192.168.10.16", "beijing"),
Message("6", "192.168.10.17", "beijing"),
Message("6", "192.168.10.18", "beijing"),
Message("5", "192.168.10.18", "shanghai"),
Message("6", "192.168.10.19", "beijing"),
Message("6", "192.168.10.19", "beijing"),
Message("5", "192.168.10.18", "shanghai")
)
)
//定义模式
val loginbeijingPattern = Pattern.begin[Message]("start")
.where(_.msg != null) //一条登录失败
.times(5).optional //将满足五次的数据配对打印
.within(Time.seconds(10))
//进行分组匹配
val loginbeijingDataPattern = CEP.pattern(loginEventStream.keyBy(_.userId), loginbeijingPattern)
//查找符合规则的数据
val loginbeijingResult: DataStream[Option[Iterable[Message]]] = loginbeijingDataPattern.select(patternSelectFun = (pattern: collection.Map[String, Iterable[Message]]) => {
var loginEventList: Option[Iterable[Message]] = null
loginEventList = pattern.get("start") match {
case Some(value) => {
if (value.toList.map(x => (x.userId, x.msg)).distinct.size == 1) {
Some(value)
} else {
None
}
}
}
loginEventList
})
//打印测试
loginbeijingResult.filter(x=>x!=None).map(x=>{
x match {
case Some(value)=> value
}
}).print()
env.execute("BarrageBehavior02)
}
}
4. Flink CEP API
除了案例中介绍的几个API外,我们在介绍下其他的常用API:
1) 条件 API
为了让传入事件被模式所接受,给模式指定传入事件必须满足的条件,这些条件由事件本身的属性或者前面匹配过的事件的属性统计量等来设定。比如,事件的某个值大于5,或者大于先前接受事件的某个值的平均值。
可以使用pattern.where()、pattern.or()、pattern.until()方法来指定条件。条件既可以是迭代条件IterativeConditions,也可以是简单条件SimpleConditions。
FlinkCEP支持事件之间的三种临近条件:
next():严格的满足条件
示例:模式为begin("first").where(_.name='a').next("second").where(.name='b')当且仅当数据为a,b时,模式才会被命中。如果数据为a,c,b,由于a的后面跟了c,所以a会被直接丢弃,模式不会命中。
followedBy():松散的满足条件
示例:模式为begin("first").where(_.name='a').followedBy("second").where(.name='b')当且仅当数据为a,b或者为a,c,b,模式均被命中,中间的c会被忽略掉。
followedByAny():非确定的松散满足条件
示例:模式为begin("first").where(_.name='a').followedByAny("second").where(.name='b')当且仅当数据为a,c,b,b时,对于followedBy模式而言命中的为{a,b},对于followedByAny而言会有两次命中{a,b},{a,b}。
2) 量词 API
还记得我们在上面讲解模式的概念时说过的一句话嘛:一般情况下,模式都是单例模式,可以使用量词(Quantifiers)将其转换为循环模式。这里的量词就是指的量词API。
以下这几个量词API,可以将模式指定为循环模式:
pattern.oneOrMore():一个给定的事件有一次或多次出现,例如上面提到的b+。
pattern.times(#ofTimes):一个给定类型的事件出现了指定次数,例如4次。
pattern.times(#fromTimes, #toTimes):一个给定类型的事件出现的次数在指定次数范围内,例如2~4次。
可以使用pattern.greedy()方法将模式变成循环模式,但是不能让一组模式都变成循环模式。greedy:就是尽可能的重复。
使用pattern.optional()方法将循环模式变成可选的,即可以是循环模式也可以是单个模式。
3) 匹配后的跳过策略
所谓的匹配跳过策略,是对多个成功匹配的模式进行筛选。也就是说如果多个匹配成功,可能我不需要这么多,按照匹配策略,过滤下就可以。
Flink中有五种跳过策略:
NO_SKIP: 不过滤,所有可能的匹配都会被发出。
SKIP_TO_NEXT: 丢弃与开始匹配到的事件相同的事件,发出开始匹配到的事件,即直接跳到下一个模式匹配到的事件,以此类推。
SKIP_PAST_LAST_EVENT: 丢弃匹配开始后但结束之前匹配到的事件。
SKIP_TO_FIRST[PatternName]: 丢弃匹配开始后但在PatternName模式匹配到的第一个事件之前匹配到的事件。
SKIP_TO_LAST[PatternName]: 丢弃匹配开始后但在PatternName模式匹配到的最后一个事件之前匹配到的事件。
怎么理解上述策略,我们以NO_SKIP和SKIP_PAST_LAST_EVENT为例讲解下:
在模式为:begin("start").where(_.name='a').oneOrMore().followedBy("second").where(_.name='b')中,我们输入数据:a,a,a,a,b ,如果是NO_SKIP策略,即不过滤策略,模式匹配到的是:{a,b},{a,a,b},{a,a,a,b},{a,a,a,a,b};如果是SKIP_PAST_LAST_EVENT策略,即丢弃匹配开始后但结束之前匹配到的事件,模式匹配到的是:{a,a,a,a,b}。
5. Flink CEP 的使用场景
除上述案例场景外,Flink CEP 还广泛用于网络欺诈,故障检测,风险规避,智能营销等领域。
1) 实时反作弊和风控
对于电商来说,羊毛党是必不可少的,国内拼多多曾爆出 100 元的无门槛券随便领,当晚被人褥几百亿,对于这种情况肯定是没有做好及时的风控。另外还有就是商家上架商品时通过频繁修改商品的名称和滥用标题来提高搜索关键字的排名、批量注册一批机器账号快速刷单来提高商品的销售量等作弊行为,各种各样的作弊手法也是需要不断的去制定规则去匹配这种行为。
2) 实时营销
分析用户在手机 APP 的实时行为,统计用户的活动周期,通过为用户画像来给用户进行推荐。比如用户在登录 APP 后 1 分钟内只浏览了商品没有下单;用户在浏览一个商品后,3 分钟内又去查看其他同类的商品,进行比价行为;用户商品下单后 1 分钟内是否支付了该订单。如果这些数据都可以很好的利用起来,那么就可以给用户推荐浏览过的类似商品,这样可以大大提高购买率。
3) 实时网络攻击检测
当下互联网安全形势仍然严峻,网络攻击屡见不鲜且花样众多,这里我们以 DDOS(分布式拒绝服务攻击)产生的流入流量来作为遭受攻击的判断依据。对网络遭受的潜在攻击进行实时检测并给出预警,云服务厂商的多个数据中心会定时向监控中心上报其瞬时流量,如果流量在预设的正常范围内则认为是正常现象,不做任何操作;如果某数据中心在 10 秒内连续 5 次上报的流量超过正常范围的阈值,则触发一条警告的事件;如果某数据中心 30 秒内连续出现 30 次上报的流量超过正常范围的阈值,则触发严重的告警。
6. Flink CEP 的原理简单介绍
Apache Flink在实现CEP时借鉴了Efficient Pattern Matching over Event Streams论文中NFA的模型,在这篇论文中,还提到了一些优化,我们在这里先跳过,只说下NFA的概念。
在这篇论文中,提到了NFA,也就是Non-determined Finite Automaton,叫做不确定的有限状态机,指的是状态有限,但是每个状态可能被转换成多个状态(不确定)。
非确定有限自动状态机
先介绍两个概念:
状态:状态分为三类,起始状态、中间状态和最终状态。
转换:take/ignore/proceed都是转换的名称。
在NFA匹配规则里,本质上是一个状态转换的过程。三种转换的含义如下所示:
Take: 主要是条件的判断,当过来一条数据进行判断,一旦满足条件,获取当前元素,放入到结果集中,然后将当前状态转移到下一个的状态。
Proceed:当前的状态可以不依赖任何的事件转移到下一个状态,比如说透传的意思。
Ignore:当一条数据到来的时候,可以忽略这个消息事件,当前的状态保持不变,相当于自己到自己的一个状态。
NFA的特点:在NFA中,给定当前状态,可能有多个下一个状态。可以随机选择下一个状态,也可以并行(同时)选择下一个状态。输入符号可以为空。
7. 规则引擎
规则引擎:将业务决策从应用程序代码中分离出来,并使用预定义的语义模块编写业务决策。接受数据输入,解释业务规则,并根据业务规则做出业务决策。
使用规则引擎可以通过降低实现复杂业务逻辑的组件的复杂性,降低应用程序的维护和可扩展性成本。
1) Drools
Drools 是一款使用 Java 编写的开源规则引擎,通常用来解决业务代码与业务规则的分离,它内置的 Drools Fusion 模块也提供 CEP 的功能。
优势:
功能较为完善,具有如系统监控、操作平台等功能。规则支持动态更新。
劣势:
以内存实现时间窗功能,无法支持较长跨度的时间窗。无法有效支持定时触达(如用户在浏览发生一段时间后触达条件判断)。2) Aviator
Aviator 是一个高性能、轻量级的 Java 语言实现的表达式求值引擎,主要用于各种表达式的动态求值。
优势:
支持大部分运算操作符。支持函数调用和自定义函数。支持正则表达式匹配。支持传入变量并且性能优秀。
劣势:
没有 if else、do while 等语句,没有赋值语句,没有位运算符。3) EasyRules
EasyRules 集成了 MVEL 和 SpEL 表达式的一款轻量级规则引擎。
优势:
轻量级框架,学习成本低。基于 POJO。为定义业务引擎提供有用的抽象和简便的应用。支持从简单的规则组建成复杂规则。4) Esper
Esper 设计目标为 CEP 的轻量级解决方案,可以方便的嵌入服务中,提供 CEP 功能。
优势:
轻量级可嵌入开发,常用的 CEP 功能简单好用。EPL 语法与 SQL 类似,学习成本较低。
劣势:
单机全内存方案,需要整合其他分布式和存储。以内存实现时间窗功能,无法支持较长跨度的时间窗。无法有效支持定时触达(如用户在浏览发生一段时间后触达条件判断)。5) Flink CEP
Flink 是一个流式系统,具有高吞吐低延迟的特点,Flink CEP 是一套极具通用性、易于使用的实时流式事件处理方案。
优势:
继承了 Flink 高吞吐的特点。事件支持存储到外部,可以支持较长跨度的时间窗。可以支持定时触达(用 followedBy + PartternTimeoutFunction 实现)。十、Flink CDC1. CDC是什么
CDC 是 Change Data Capture(变更数据获取)的简称。核心思想是,监测并捕获数据库的变动(包括数据或数据表的插入、更新以及删除等),将这些变更按发生的顺序完整记录下来,写入到消息中间件中以供其他服务进行订阅及消费。
在广义的概念上,只要能捕获数据变更的技术,我们都可以称为 CDC 。通常我们说的 CDC 技术主要面向数据库的变更,是一种用于捕获数据库中数据变更的技术。
CDC 技术应用场景非常广泛:
数据同步,用于备份,容灾;
数据分发,一个数据源分发给多个下游;
数据采集(E),面向数据仓库/数据湖的 ETL 数据集成。
2. CDC 的种类
CDC 主要分为基于查询和基于 Binlog 两种方式,我们主要了解一下这两种之间的区别:
基于查询的 CDC基于 Binlog 的 CDC开源产品Sqoop、Kafka JDBC SourceCanal、Maxwell、Debezium执行模式BatchStreaming是否可以捕获所有数据变化否是延迟性高延迟低延迟是否增加数据库压力是否3. 传统CDC与Flink CDC对比1) 传统 CDC ETL 分析

2) 基于 Flink CDC 的 ETL 分析

2) 基于 Flink CDC 的聚合分析

2) 基于 Flink CDC 的数据打宽

4. Flink-CDC 案例
Flink 社区开发了 flink-cdc-connectors 组件,这是一个可以直接从 MySQL、PostgreSQL等数据库直接读取全量数据和增量变更数据的 source 组件。
开源地址:https://github.com/ververica/flink-cdc-connectors。
示例代码:
import com.alibaba.ververica.cdc.connectors.mysql.MySQLSource;
import com.alibaba.ververica.cdc.debezium.DebeziumSourceFunction;
import com.alibaba.ververica.cdc.debezium.StringDebeziumDeserializationSchema;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.runtime.state.filesystem.FsStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.Properties;
public class FlinkCDC {
public static void main(String[] args) throws Exception {
//1.创建执行环境
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//2.Flink-CDC 将读取 binlog 的位置信息以状态的方式保存在 CK,如果想要做到断点
续传,需要从 Checkpoint 或者 Savepoint 启动程序
//2.1 开启 Checkpoint,每隔 5 秒钟做一次 CK
env.enableCheckpointing(5000L);
//2.2 指定 CK 的一致性语义
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//2.3 设置任务关闭的时候保留最后一次 CK 数据
env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckp
ointCleanup.RETAIN_ON_CANCELLATION);
//2.4 指定从 CK 自动重启策略
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3, 2000L));
//2.5 设置状态后端
env.setStateBackend(new FsStateBackend("hdfs://hadoop102:8020/flinkCDC"));
//2.6 设置访问 HDFS 的用户名
System.setProperty("HADOOP_USER_NAME", "atguigu");
//3.创建 Flink-MySQL-CDC 的 Source
//initial (default): Performs an initial snapshot on the monitored database tables upon
first startup, and continue to read the latest binlog.
//latest-offset: Never to perform snapshot on the monitored database tables upon first
startup, just read from the end of the binlog which means only have the changes since the
connector was started.
//timestamp: Never to perform snapshot on the monitored database tables upon first
startup, and directly read binlog from the specified timestamp. The consumer will traverse the
binlog from the beginning and ignore change events whose timestamp is smaller than the
specified timestamp.
//specific-offset: Never to perform snapshot on the monitored database tables upon
first startup, and directly read binlog from the specified offset.
DebeziumSourceFunction
虽然实时计算在最近几年才火起来,但是在早期也有部分公司有实时计算的需求,但是数据量比较少,所以在实时方面形成不了完整的体系,基本所有的开发都是具体问题具体分析,来一个需求做一个,基本不考虑它们之间的关系,开发形式如下:

早期实时计算
如上图所示,拿到数据源后,会经过数据清洗,扩维,通过Flink进行业务逻辑处理,最后直接进行业务输出。把这个环节拆开来看,数据源端会重复引用相同的数据源,后面进行清洗、过滤、扩维等操作,都要重复做一遍,唯一不同的是业务的代码逻辑是不一样的。
随着产品和业务人员对实时数据需求的不断增多,这种开发模式出现的问题越来越多:
数据指标越来越多,“烟囱式”的开发导致代码耦合问题严重。
需求越来越多,有的需要明细数据,有的需要 OLAP 分析。单一的开发模式难以应付多种需求。
每个需求都要申请资源,导致资源成本急速膨胀,资源不能集约有效利用。
缺少完善的监控系统,无法在对业务产生影响之前发现并修复问题。
大家看实时数仓的发展和出现的问题,和离线数仓非常类似,后期数据量大了之后产生了各种问题,离线数仓当时是怎么解决的?离线数仓通过分层架构使数据解耦,多个业务可以共用数据,实时数仓是否也可以用分层架构呢?当然是可以的,但是细节上和离线的分层还是有一些不同,稍后会讲到。
2. 实时数仓建设
从方法论来讲,实时和离线是非常相似的,离线数仓早期的时候也是具体问题具体分析,当数据规模涨到一定量的时候才会考虑如何治理。分层是一种非常有效的数据治理方式,所以在实时数仓如何进行管理的问题上,首先考虑的也是分层的处理逻辑。
实时数仓的架构如下图:

实时数仓架构
从上图中我们具体分析下每层的作用:
数据源:在数据源的层面,离线和实时在数据源是一致的,主要分为日志类和业务类,日志类又包括用户日志,埋点日志以及服务器日志等。
实时明细层:在明细层,为了解决重复建设的问题,要进行统一构建,利用离线数仓的模式,建设统一的基础明细数据层,按照主题进行管理,明细层的目的是给下游提供直接可用的数据,因此要对基础层进行统一的加工,比如清洗、过滤、扩维等。
汇总层:汇总层通过Flink的简洁算子直接可以算出结果,并且形成汇总指标池,所有的指标都统一在汇总层加工,所有人按照统一的规范管理建设,形成可复用的汇总结果。
我们可以看出,实时数仓和离线数仓的分层非常类似,比如 数据源层,明细层,汇总层,乃至应用层,他们命名的模式可能都是一样的。但仔细比较不难发现,两者有很多区别:
与离线数仓相比,实时数仓的层次更少一些:
从目前建设离线数仓的经验来看,数仓的数据明细层内容会非常丰富,处理明细数据外一般还会包含轻度汇总层的概念,另外离线数仓中应用层数据在数仓内部,但实时数仓中,app 应用层数据已经落入应用系统的存储介质中,可以把该层与数仓的表分离。
应用层少建设的好处:实时处理数据的时候,每建一个层次,数据必然会产生一定的延迟。
汇总层少建的好处:在汇总统计的时候,往往为了容忍一部分数据的延迟,可能会人为的制造一些延迟来保证数据的准确。举例,在统计跨天相关的订单事件中的数据时,可能会等到 00:00:05 或者 00:00:10 再统计,确保 00:00 前的数据已经全部接受到位了,再进行统计。所以,汇总层的层次太多的话,就会更大的加重人为造成的数据延迟。
与离线数仓相比,实时数仓的数据源存储不同:
在建设离线数仓的时候,基本整个离线数仓都是建立在 Hive 表之上。但是,在建设实时数仓的时候,同一份表,会使用不同的方式进行存储。比如常见的情况下,明细数据或者汇总数据都会存在 Kafka 里面,但是像城市、渠道等维度信息需要借助 Hbase,MySQL 或者其他 KV 存储等数据库来进行存储。3. Lambda架构的实时数仓
Lambda和Kappa架构的概念已在前文中解释,不了解的小伙伴可点击链接:一文读懂大数据实时计算
下图是基于 Flink 和 Kafka 的 Lambda 架构的具体实践,上层是实时计算,下层是离线计算,横向是按计算引擎来分,纵向是按实时数仓来区分:

Lambda架构的实时数仓
Lambda架构是比较经典的架构,以前实时的场景不是很多,以离线为主,当附加了实时场景后,由于离线和实时的时效性不同,导致技术生态是不一样的。Lambda架构相当于附加了一条实时生产链路,在应用层面进行一个整合,双路生产,各自独立。这在业务应用中也是顺理成章采用的一种方式。
双路生产会存在一些问题,比如加工逻辑double,开发运维也会double,资源同样会变成两个资源链路。因为存在以上问题,所以又演进了一个Kappa架构。
4. Kappa架构的实时数仓
Kappa架构相当于去掉了离线计算部分的Lambda架构,具体如下图所示:

Kappa架构的实时数仓
Kappa架构从架构设计来讲比较简单,生产统一,一套逻辑同时生产离线和实时。但是在实际应用场景有比较大的局限性,因为实时数据的同一份表,会使用不同的方式进行存储,这就导致关联时需要跨数据源,操作数据有很大局限性,所以在业内直接用Kappa架构生产落地的案例不多见,且场景比较单一。
关于 Kappa 架构,熟悉实时数仓生产的同学,可能会有一个疑问。因为我们经常会面临业务变更,所以很多业务逻辑是需要去迭代的。之前产出的一些数据,如果口径变更了,就需要重算,甚至重刷历史数据。对于实时数仓来说,怎么去解决数据重算问题?
Kappa 架构在这一块的思路是:首先要准备好一个能够存储历史数据的消息队列,比如 Kafka,并且这个消息队列是可以支持你从某个历史的节点重新开始消费的。接着需要新起一个任务,从原来比较早的一个时间节点去消费 Kafka 上的数据,然后当这个新的任务运行的进度已经能够和现在的正在跑的任务齐平的时候,你就可以把现在任务的下游切换到新的任务上面,旧的任务就可以停掉,并且原来产出的结果表也可以被删掉。
5. 流批结合的实时数仓
随着实时 OLAP 技术的发展,目前开源的OLAP引擎在性能,易用等方面有了很大的提升,如Doris、Presto等,加上数据湖技术的迅速发展,使得流批结合的方式变得简单。
如下图是流批结合的实时数仓:

流批结合的实时数仓
数据从日志统一采集到消息队列,再到实时数仓,作为基础数据流的建设是统一的。之后对于日志类实时特征,实时大屏类应用走实时流计算。对于Binlog类业务分析走实时OLAP批处理。
我们看到流批结合的方式与上面几种架构的存储方式发生了变化,由Kafka换成了Iceberg,Iceberg是介于上层计算引擎和底层存储格式之间的一个中间层,我们可以把它定义成一种“数据组织格式”,底层存储还是HDFS,那么为什么加了中间层,就对流批结合处理的比较好了呢?Iceberg的ACID能力可以简化整个流水线的设计,降低整个流水线的延迟,并且所具有的修改、删除能力能够有效地降低开销,提升效率。Iceberg可以有效支持批处理的高吞吐数据扫描和流计算按分区粒度并发实时处理。
十二、Flink 面试题1. Flink 的容错机制(checkpoint)
Checkpoint机制是Flink可靠性的基石,可以保证Flink集群在某个算子因为某些原因(如 异常退出)出现故障时,能够将整个应用流图的状态恢复到故障之前的某一状态,保证应用流图状态的一致性。Flink的Checkpoint机制原理来自“Chandy-Lamport algorithm”算法。
每个需要Checkpoint的应用在启动时,Flink的JobManager为其创建一个 CheckpointCoordinator(检查点协调器),CheckpointCoordinator全权负责本应用的快照制作。
CheckpointCoordinator(检查点协调器),CheckpointCoordinator全权负责本应用的快照制作。

CheckpointCoordinator(检查点协调器) 周期性的向该流应用的所有source算子发送 barrier(屏障)。
当某个source算子收到一个barrier时,便暂停数据处理过程,然后将自己的当前状态制作成快照,并保存到指定的持久化存储中,最后向CheckpointCoordinator报告自己快照制作情况,同时向自身所有下游算子广播该barrier,恢复数据处理
下游算子收到barrier之后,会暂停自己的数据处理过程,然后将自身的相关状态制作成快照,并保存到指定的持久化存储中,最后向CheckpointCoordinator报告自身快照情况,同时向自身所有下游算子广播该barrier,恢复数据处理。
每个算子按照步骤3不断制作快照并向下游广播,直到最后barrier传递到sink算子,快照制作完成。
当CheckpointCoordinator收到所有算子的报告之后,认为该周期的快照制作成功; 否则,如果在规定的时间内没有收到所有算子的报告,则认为本周期快照制作失败。
文章推荐:
Flink可靠性的基石-checkpoint机制详细解析
2. Flink Checkpoint与 Spark 的相比,Flink 有什么区别或优势吗
Spark Streaming 的 Checkpoint 仅仅是针对 Driver 的故障恢复做了数据和元数据的 Checkpoint。而 Flink 的 Checkpoint 机制要复杂了很多,它采用的是轻量级的分布式快照,实现了每个算子的快照,及流动中的数据的快照。
3. Flink 中的 Time 有哪几种
Flink中的时间有三种类型,如下图所示:
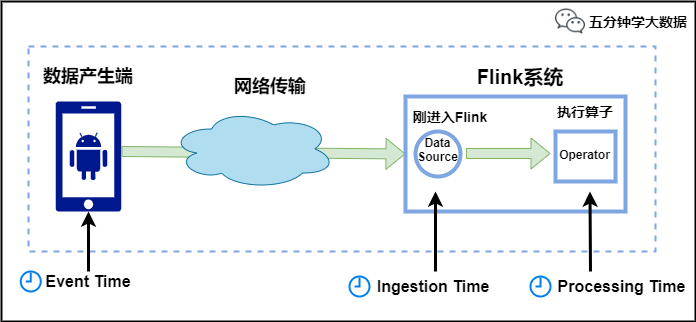
Event Time:是事件创建的时间。它通常由事件中的时间戳描述,例如采集的日志数据中,每一条日志都会记录自己的生成时间,Flink通过时间戳分配器访问事件时间戳。
Ingestion Time:是数据进入Flink的时间。
Processing Time:是每一个执行基于时间操作的算子的本地系统时间,与机器相关,默认的时间属性就是Processing Time。
例如,一条日志进入Flink的时间为2021-01-22 10:00:00.123,到达Window的系统时间为2021-01-22 10:00:01.234,日志的内容如下:
2021-01-06 18:37:15.624 INFO Fail over to rm2
对于业务来说,要统计1min内的故障日志个数,哪个时间是最有意义的?—— eventTime,因为我们要根据日志的生成时间进行统计。
4. 对于迟到数据是怎么处理的
Flink中 WaterMark 和 Window 机制解决了流式数据的乱序问题,对于因为延迟而顺序有误的数据,可以根据eventTime进行业务处理,对于延迟的数据Flink也有自己的解决办法,主要的办法是给定一个允许延迟的时间,在该时间范围内仍可以接受处理延迟数据:
设置允许延迟的时间是通过allowedLateness(lateness: Time)设置
保存延迟数据则是通过sideOutputLateData(outputTag: OutputTag[T])保存
获取延迟数据是通过DataStream.getSideOutput(tag: OutputTag[X])获取
文章推荐:
Flink 中极其重要的 Time 与 Window 详细解析
5. Flink 的运行必须依赖 Hadoop 组件吗
Flink可以完全独立于Hadoop,在不依赖Hadoop组件下运行。但是做为大数据的基础设施,Hadoop体系是任何大数据框架都绕不过去的。Flink可以集成众多Hadooop 组件,例如Yarn、Hbase、HDFS等等。例如,Flink可以和Yarn集成做资源调度,也可以读写HDFS,或者利用HDFS做检查点。
6. Flink集群有哪些角色?各自有什么作用
有以下三个角色:
JobManager处理器:
也称之为Master,用于协调分布式执行,它们用来调度task,协调检查点,协调失败时恢复等。Flink运行时至少存在一个master处理器,如果配置高可用模式则会存在多个master处理器,它们其中有一个是leader,而其他的都是standby。
TaskManager处理器:
也称之为Worker,用于执行一个dataflow的task(或者特殊的subtask)、数据缓冲和data stream的交换,Flink运行时至少会存在一个worker处理器。
Clint客户端:
Client是Flink程序提交的客户端,当用户提交一个Flink程序时,会首先创建一个Client,该Client首先会对用户提交的Flink程序进行预处理,并提交到Flink集群中处理,所以Client需要从用户提交的Flink程序配置中获取JobManager的地址,并建立到JobManager的连接,将Flink Job提交给JobManager
7. Flink 资源管理中 Task Slot 的概念
在Flink中每个TaskManager是一个JVM的进程, 可以在不同的线程中执行一个或多个子任务。为了控制一个worker能接收多少个task。worker通过task slot(任务槽)来进行控制(一个worker至少有一个task slot)。
8. Flink的重启策略了解吗
Flink支持不同的重启策略,这些重启策略控制着job失败后如何重启:
固定延迟重启策略
固定延迟重启策略会尝试一个给定的次数来重启Job,如果超过了最大的重启次数,Job最终将失败。在连续的两次重启尝试之间,重启策略会等待一个固定的时间。
失败率重启策略
失败率重启策略在Job失败后会重启,但是超过失败率后,Job会最终被认定失败。在两个连续的重启尝试之间,重启策略会等待一个固定的时间。
无重启策略
Job直接失败,不会尝试进行重启。
9. Flink 是如何保证 Exactly-once 语义的
Flink通过实现两阶段提交和状态保存来实现端到端的一致性语义。分为以下几个步骤:
开始事务(beginTransaction)创建一个临时文件夹,来写把数据写入到这个文件夹里面
预提交(preCommit)将内存中缓存的数据写入文件并关闭
正式提交(commit)将之前写完的临时文件放入目标目录下。这代表着最终的数据会有一些延迟
丢弃(abort)丢弃临时文件
若失败发生在预提交成功后,正式提交前。可以根据状态来提交预提交的数据,也可删除预提交的数据。
文章推荐:
八张图搞懂 Flink 端到端精准一次处理语义 Exactly-once
10. 如果下级存储不支持事务,Flink 怎么保证 exactly-once
端到端的 exactly-once 对 sink 要求比较高,具体实现主要有幂等写入和事务性写入两种方式。
幂等写入的场景依赖于业务逻辑,更常见的是用事务性写入。而事务性写入又有预写日志(WAL)和两阶段提交(2PC)两种方式。
如果外部系统不支持事务,那么可以用预写日志的方式,把结果数据先当成状态保存,然后在收到 checkpoint 完成的通知时,一次性写入 sink 系统。
11. Flink是如何处理反压的
Flink 内部是基于 producer-consumer 模型来进行消息传递的,Flink的反压设计也是基于这个模型。Flink 使用了高效有界的分布式阻塞队列,就像 Java 通用的阻塞队列(BlockingQueue)一样。下游消费者消费变慢,上游就会受到阻塞。
12. Flink中的状态存储
Flink在做计算的过程中经常需要存储中间状态,来避免数据丢失和状态恢复。选择的状态存储策略不同,会影响状态持久化如何和 checkpoint 交互。Flink提供了三种状态存储方式:MemoryStateBackend、FsStateBackend、RocksDBStateBackend。
13. Flink是如何支持流批一体的
这道题问的比较开阔,如果知道Flink底层原理,可以详细说说,如果不是很了解,就直接简单一句话:Flink的开发者认为批处理是流处理的一种特殊情况。批处理是有限的流处理。Flink 使用一个引擎支持了 DataSet API 和 DataStream API。
14. Flink的内存管理是如何做的
Flink 并不是将大量对象存在堆上,而是将对象都序列化到一个预分配的内存块上。此外,Flink大量的使用了堆外内存。如果需要处理的数据超出了内存限制,则会将部分数据存储到硬盘上。Flink 为了直接操作二进制数据实现了自己的序列化框架。
15. Flink CEP 编程中当状态没有到达的时候会将数据保存在哪里
在流式处理中,CEP 当然是要支持 EventTime 的,那么相对应的也要支持数据的迟到现象,也就是watermark的处理逻辑。CEP对未匹配成功的事件序列的处理,和迟到数据是类似的。在 Flink CEP的处理逻辑中,状态没有满足的和迟到的数据,都会存储在一个Map数据结构中,也就是说,如果我们限定判断事件序列的时长为5分钟,那么内存中就会存储5分钟的数据,这在我看来,也是对内存的极大损伤之一。
最后
第一时间获取最新大数据技术,尽在本公众号:五分钟学大数据

 分享
分享








最新活动更多

先进LED照明系统,引领未来趋势新标杆")


-
10 阿里AI需要算一笔账了
- 1 GPT-6要来了,但AI行业早不跟 OpenAI玩了
- 2 火爆的“Token经济学”,关乎你的钱包、职场和未来消费 | 人人能懂的产业报告
- 3 资本巨头纷纷抽身,为何中小投资者仍为AI狂热加码?
- 4 大厂财报中的AI图鉴:营收单列、玩杠杆、商业画饼
- 5 从百度到Meta,科技巨头的 AI 组织战,开打了
- 6 2026年3月,国内具身智能机器人企业融资汇总
- 7 华勤财报发布:收入规模破1700亿,利润增长近40%
- 8 宇树科技招股书透视:中外具身智能玩家生存竞速
- 9 大涨30%!智谱 AI 财报出炉:营收暴增132%,API 增长3倍,市值破 4000 亿
- 10 谷歌Gemma 4遭破解!实测:伪造支票、找盗版电影,有求必应



发表评论
登录
手机
验证码
手机/邮箱/用户名
密码
立即登录即可访问所有OFweek服务
还不是会员?免费注册
忘记密码其他方式
请输入评论内容...
请输入评论/评论长度6~500个字
暂无评论
暂无评论