









深兰拿下首届 LargeFineFoodAI赛道冠军
日前,两年一度的计算机视觉领域顶级学术会议 ICCV 在加拿大蒙特利尔圆满闭幕。在此期间,与大会同期举行的首届LargeFineFoodAI技术研讨会,由美团视觉智能中心联合中科院计算所、北京智源、巴塞罗那大学在Kaggle竞赛平台上共同主办,会议核心聚焦计算机视觉技术在大规模细粒度食品分析领域的应用。
首届 LargeFineFoodAI 比赛分为 Recognition 和 Retrieval 两个赛道,根据研讨会评选结果得知,深兰DeepBlueAI团队在Large-ScaleFine-Grained Food Retrieval 赛道中取得了冠军的成绩。
01
赛题介绍
与通用图像识别及检索相比,食品细粒度识别及检索技术难度更大。许多不同类型的食品外观看起来可能非常相近,而同一种类型的食品也可能由于做法不同看起来差异较大,此外光线、拍摄角度、不同的拍摄背景都可能对算法的精度产生影响,即便对于专业人员也较难快速准确的进行辨别。
另一方面,相关技术具有广泛的应用场景和实际的应用价值,例如降低商家端食品图片的审核成本,提升C端食品图片和视频的分发效率等。美团作为国内领先的生活服务平台,准确把握住消费升级趋势给餐饮行业的经营、消费方式带来的革命性变化,率先提出借助计算机视觉算法对食品图像进行细粒度分析,来快速响应和满足商户和用户大量多样的在线食品图像审核、管理、浏览、评价等需求。

本次挑战赛所用数据集来自美团自建数据集"Food2K",该数据集每一张美食图片均由不同个人,采用不同设备,在不同环境场景下拍摄获取,是难得的可以公正评价算法鲁棒性和效果的图片数据,挑战也非常大。并且所有图像均由美团公司的食品专家进行评估,确保了数据的高质量。相比其他主流食品图像识别数据集,"Food2K"数据集完全人工标注,数据集噪声比例控制在 1% 以内;数据分布与真实场景相符,不平衡现象显著;而且类别粒度更细。以披萨为例,主流数据集(例如Food-101)仅具有披萨类,而"Food2K"进一步将其划分为多种多样的披萨,如鲜虾披萨、榴莲披萨等。


02
评测指标
此外,为了进一步推进食品视觉分析领域的研究与实践,吸引更多行业相关团队关注参与,美团发起了以LargeFineFoodAI为主题的挑战赛。该竞赛将分为两大赛道,其一是“大规模食品图像细粒度识别”,将采用Food1K数据集(包含1500种类别中的1000种食物类别),通过Top-1分类准确率进行算法评估;其二是“大规模食品图像细粒度检索”,将使用同赛道一的训练和验证集,使用剩余的Food500作为测试集,使用MAP@100进行算法评估。
03
团队成绩

团队成绩排名

获奖证书
04
题目特点以及常用方法
图像检问题现有研究比较多,但对于大规模、细粒度的图像检索比较新。图像检索最主要的就是特征提取网络,现有的的特征提取网络主要基于卷积神经网络如ResNet、ResNest和EfficientNet等,无法像transformer一样提取到更加丰富、区分度更高的特征。提取完特征后,在度量两张图片相似度的阶段单纯使用余弦距离来计算精度很低,DeepBlueAI团队使用ReRank的方法将欧式距离和雅可比距离加权来度量query和gallery之间的相似度。
05
比赛数据与数据分析
本次比赛数据集包含超过1000个细粒度食物类别和超过50000张图像的数据集。它包含西餐和中餐,每个类别的图像数量在范围内[153; 1999],与现有的食物数据集相比,显示出更大的类别不平衡。下图显示了它的本体和数据集的详细统计信息:


从图中可以看出,LargeFoodAI数据集,具有类别多、细粒度和类别不平衡等特点。
06
PIPELINE
如下图所示,DeepBlueAI团队首先采用五折交叉验证的方法对数据进行划分;然后用Swin Transfomrer作为主干网络提取特征;接着用BNNeck模块对所提特征进行归一化操作;最后使用交叉熵和label smooth函数对模型进行优化。
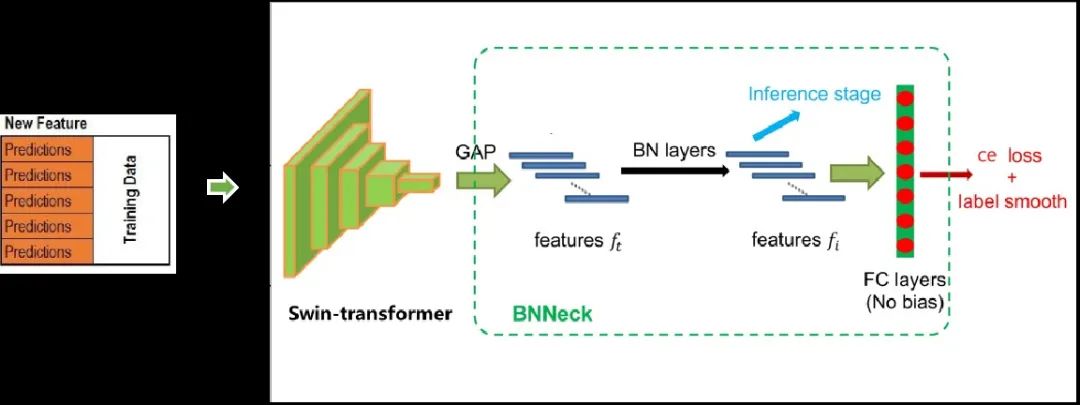
07
实验模型
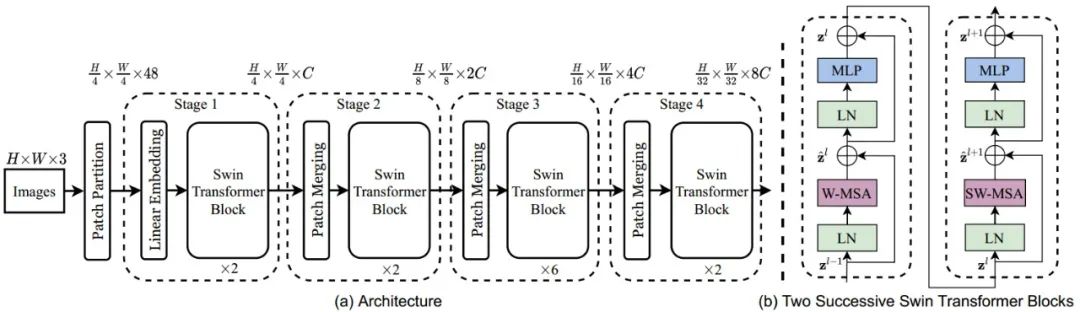
Swin Transforme主干网络
DeepBlueAI团队基于Swin Transformer主要实验了4种结构,swin_base_224, swin_base_384、swin_large_224和swin_large_384模型。下图为Swin Transfomer的结构图:
Sharpness-AwareMinimization
(SAM)优化器
SAM优化器通过一种新的、有效的方法来同时减小损失值和损失的锐度,在领域内寻找具有均匀的低损失值的参数。该方法通过求解最小-最大优化问题,使得梯度下降可以有效地执行,在各种基准数据集上都改善了模型得泛化能力。下图为SGD优化器和SAM优化器的示意图:

CutMix数据增强
DeepBlueAI团队采用CutMix数据增强的方法来扩充数据的多样性,同时也能提高模型对相似类别数据的区分度。

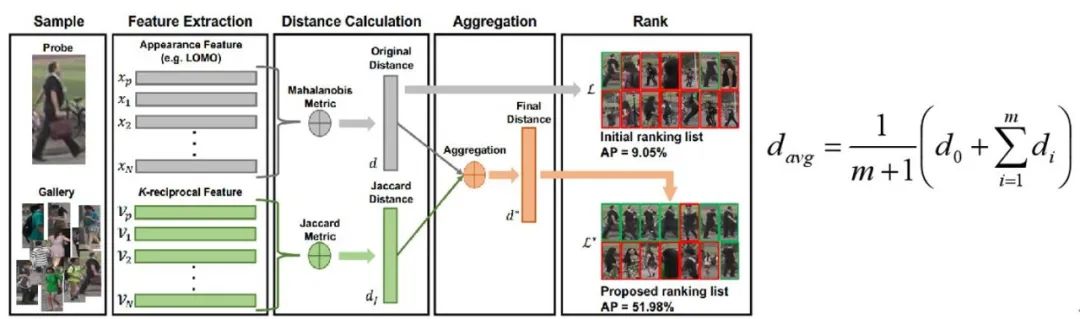
Rerank_qe
DeepBlueAI团队将所有数据中和query特征最为相似的40个特征的平均值作为新的query特征,用0.25的权值对欧式距离和雅可比距离进行加权。ReRank方式如下图所示:
08
模型融合
模型融合是算法大赛中常用的提高模型精度方法,DeepBlueAI团队最终选择了swinb_224、swinb_384、swinl_224和swinl_384等不同主干和训练尺度生成的特征进行模型融合,最终模型融合的结果为82.813mAP@100,取得了本次比赛第一的成绩。

# 深兰DeepBlueAI团队总结
我们在最初做这个任务的时候,尝试了许多基于CNN的主干网络,如ResNet、ResNeSt和EfficientNet等,但是发现这些主干网络无论分类还是检索的效果都不是很好。在分类任务使用Swin Transformer取得远优于CNN网络的效果之后,就把它移植到检索任务里来,取得了不错的成绩。在进一步的使用ReRank、Ensemble等检索任务常用trick之后,取得了检索任务第一的成绩。
在数据处理方面,我们发现CutMix方法有效的增强了不同类别之间特征的区分度。SAM优化器和LabelSmooth损失函数的采用,也进一步的提高了模型的泛化能力和识别精度。

 分享
分享








最新活动更多
-
3月27日立即报名>> 【工程师系列】汽车电子技术在线大会
-
4月30日立即下载>> 【村田汽车】汽车E/E架构革新中,新智能座舱挑战的解决方案
-
5月15-17日立即预约>> 【线下巡回】2025年STM32峰会
-
即日-5.15立即报名>>> 【在线会议】安森美Hyperlux™ ID系列引领iToF技术革新
-
5月15日立即下载>> 【白皮书】精确和高效地表征3000V/20A功率器件应用指南
-
5月16日立即参评 >> 【评选启动】维科杯·OFweek 2025(第十届)人工智能行业年度评选







发表评论
请输入评论内容...
请输入评论/评论长度6~500个字
暂无评论
暂无评论